Defending Large Language Models Against Jailbreak Attacks via Layer-specific Editing
Defending Large Language Models Against Jailbreak Attacks via Layer-specific Editing
EMNLP
1. 论文概览
- 核心问题:大语言模型(LLMs)虽经人类反馈强化学习(RLHF)或监督微调对齐,仍易受精心设计的越狱攻击生成有害内容,现有防御多聚焦于检测或降低有害响应概率,未深入LLM内部机制,亟需基于LLM内部机制的抗越狱攻击防御方法。
- 主要贡献:
- 发现LLM中仅部分早期层对识别有害提示起关键作用,移除这些层会使LLM对齐失效并生成有害响应;
- 提出层特定编辑(LED)方法,通过定位安全层与毒性层并编辑安全层,在增强LLM抗越狱攻击能力的同时保持对良性提示的性能;
- 在Llama2、Mistral等模型上验证LED有效性,能有效防御多种最先进越狱攻击,且对模型有用性影响极小。
- 研究方法:通过层剪枝分析识别关键安全层与额外防御层(编辑层),通过解码隐藏状态定位毒性层,再以毒性层的安全响应解码结果为目标,编辑安全层与额外防御层,使毒性层仅输出安全响应。
2. 各章节详解
2.1 引言(1. Introduction)
- LLM现状与问题:LLMs(如GPT4、Llama2、Mistral)在多任务中表现优异且广泛应用,但即使经过对齐优化,仍易受“越狱攻击”( adversarial prompts)诱导生成有害、有偏见内容,威胁安全部署。
- 现有防御局限:现有防御分两类——①通过困惑度过滤、输入变异或LLM自身检测有害提示/响应;②通过安全指令或logit处理器降低有害响应概率,但均易被自适应攻击突破,且未深入LLM内部工作机制。
- 研究动机:基于LLM剪枝与层跳过研究(移除部分层不影响性能)及早期层抗攻击关键作用的观察,通过层级分析识别影响LLM对有害/越狱提示响应的关键层,进而提出防御方法。
- 核心发现预览:存在关键安全层(早期层),移除后LLM对原始有害提示即生成有害响应;部分层(非全部)含触发有害响应的毒性信息,部分层仍保持高拒绝token解码概率。
2.2 相关工作(2. Related Work)
2.2.1 越狱攻击(Jailbreak Attacks)
- 早期依赖手工设计提示(如社交媒体收集的有效越狱提示)或对话模板生成提示;
- 近期聚焦自动生成提示:梯度方法(如GCG)、无梯度遗传算法、随机搜索迭代优化,或利用辅助LLM(如GPTFuzzer用预训练LLM更新模板、PAIR用攻击LLM选候选提示),但LLM在恶意语境下的脆弱性仍未被充分探索。
2.2.2 越狱防御(Jailbreak Defenses)
- 防御方法与引言分类一致,但均未全面理解LLM内在安全机制,无法从根本上抵御攻击。
2.2.3 知识编辑(Knowledge Editing)
- 目标:在特定领域修改LLM行为且不影响其他输入性能,分三类——
- 微调:用新数据集直接更新知识(如Lee et al., 2022);
- 元学习:训练超网络学习编辑模型而非直接更新权重(如KE、MEND);
- 定位-编辑:利用知识存储于MLP模块的发现,定位并编辑目标知识(如ROME、MEMIT用因果中介分析定位隐藏状态);
- 与本文差异:传统知识编辑试图“解毒”毒性层,而本文不直接编辑毒性层(无法完全消除有害知识),而是编辑安全层使毒性层输出安全响应。
2.3 LED方法(3. LED: Layer-specific Editing for Enhancing Defense of LLMs)
LED含三个核心步骤,流程如图2所示:
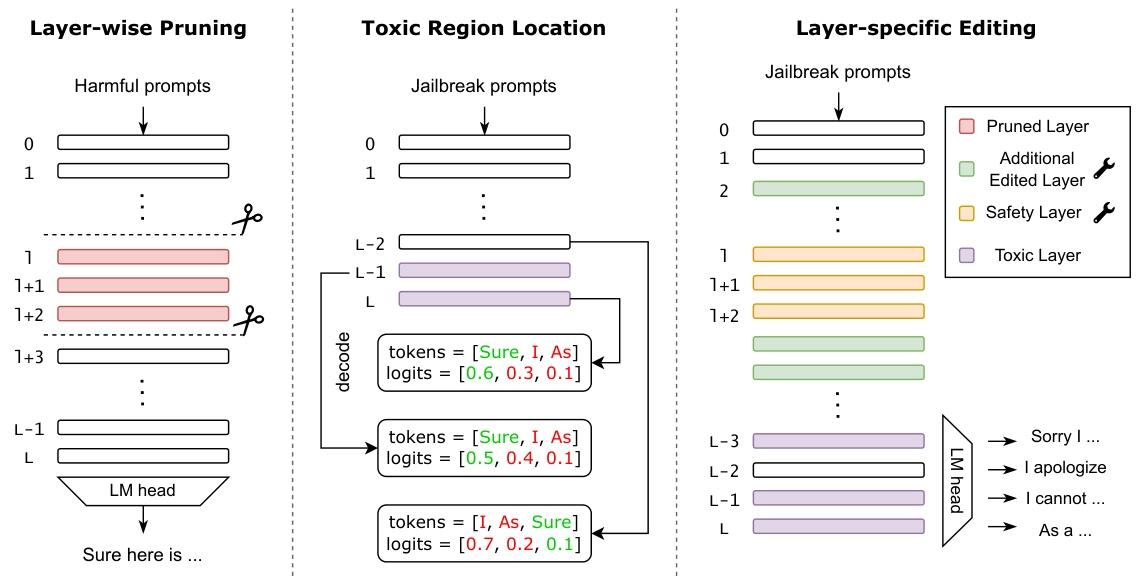
2.3.1 步骤1:选择编辑层(Selecting Edited Layers)
- 识别安全层(S):
- 过程:通过层剪枝分析,迭代移除LLM(设为L层,记为f)中1个或连续多个层(从层1开始,避免初始嵌入层;最多移除L/2层以保证输出有意义),得到剪枝模型fl, n(移除层l至l+n,1 ≤ l ≤ L,0 ≤ n ≤ min(L/2, L − l));
- 判定:若fl, n对有害提示生成有害响应,停止剪枝,层l至l+n为安全层候选;
- 筛选:用
layer_frequency统计所有有害提示下安全层候选出现频率,取top-k层为安全层S(公式2,原文未列具体公式,核心为频率排序)。
- 确定编辑层(E):将安全层S与额外防御贡献层(增强编辑鲁棒性)合并,得到最终编辑层E。
2.3.2 步骤2:定位毒性层(Locating Toxic Layers)
- 毒性层定义:含促进有害响应生成“毒性区域”的层,通过解码隐藏状态识别。
- 定位方法:输入越狱提示,用LLM原始解码层将层l的隐藏状态hl解码到词汇空间vl ∈ ℝ#vocab × 1,观察解码token概率;
- 毒性评分(T(hl)):量化层l解码输出中有害响应的比例,公式为: $$T(h_l) = \frac{v_l(t_{toxic})}{max(v_l)}$$ 其中ttoxic是LLM最终层生成的有害token,vl(ttoxic)是层l中ttoxic的概率,max(vl)是层l解码logits最大值;
- 毒性层筛选:平均毒性评分>0.5的层为毒性层(T),需对齐使其仅输出安全内容。
2.3.3 步骤3:层特定编辑(Layer-specific Editing)
- 输入输出对:采用(Xharm, Ysafe),Xharm为有害提示,Ysafe为期望安全响应;
- 编辑损失:使编辑层对齐毒性层的安全响应解码结果,损失公式为: Ledit = −logPf(Ysafe|Xharm, ht) 其中ht是毒性层t的隐藏状态;
- 模型更新:基于Ledit计算编辑层E中每层l的更新方向Δtl,更新层l权重,得到抗攻击的鲁棒模型frobust。
2.4 LLM的安全与毒性层分析(4. A Closer Look at LLMs: Safety and Toxic Layers)
2.4.1 早期安全层主导防御(Early Safety Layers Dominates Defense)
实验:对AdvBench中100个随机有害提示进行层剪枝分析(4个模型:Llama2-13B、Llama2-7B、Mistral-7B、Vicuna-7B);
结果:
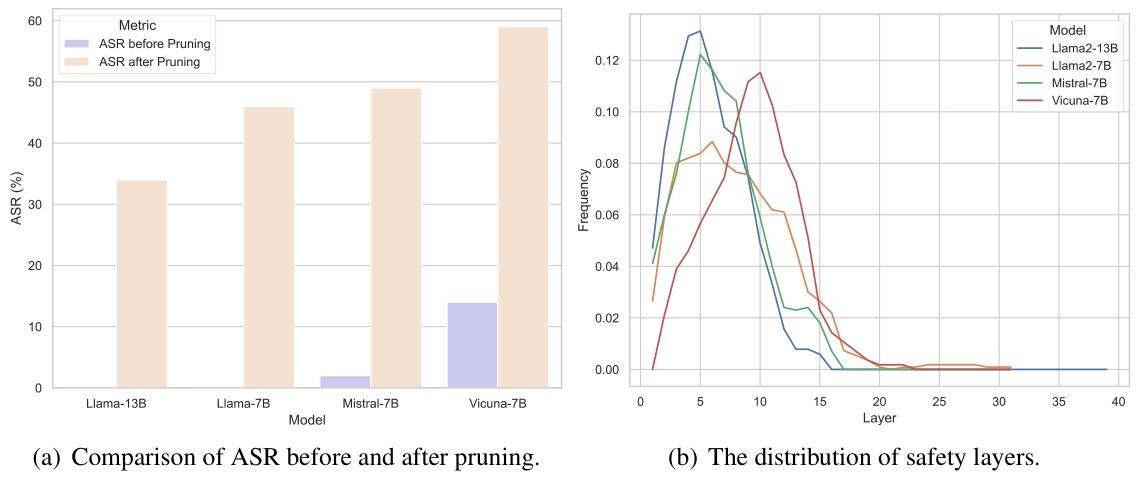
- 所有模型均存在安全层,移除后对自然有害提示的攻击成功率(ASR)显著提升(ASR越高防御越差,图3(a));
- 安全层集中在早期层(图3(b)),后期层基本不参与有害提示防御,验证早期层识别有害提示的关键作用。
2.4.2 多个后期层含毒性信息(Multiple Later Layers Contain Toxic Information)
实验:分析Llama2-7B和Mistral-7B对100个越狱提示的层毒性评分(图4);
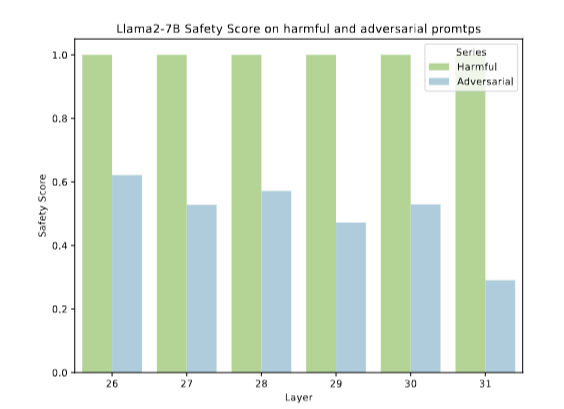
结果:后期层(非仅最终层)普遍高概率输出有害token,需对齐;但不直接编辑毒性层(无法穷尽触发有害内容的越狱提示,且无法防止新方法提取有害知识),而是通过编辑安全层使毒性层生成安全拒绝响应。
2.5 实验(5. Experiments)
2.5.1 实验设置(Experiment Setup)
- 数据集与模型:
- 攻击评估:AdvBench生成越狱提示,用攻击成功率(ASR)为指标;
- 层分析与编辑:200个来自Trojan Detection Competition 2023的有害提示(用于层剪枝与输入输出对),500个越狱提示(用于定位毒性层),两类数据集无重叠;
- 有用性评估:MT-bench、Just-Eval;
- 测试模型:强对齐模型Llama2-7B,弱对齐模型Mistral-7B。
- 攻击设置:5种最先进越狱攻击——PAIR、AutoDAN、GPTFuzzer、GCG、DeepInception,用EasyJailbreak实现,GPT-4生成攻击材料(如有害前缀/后缀)。
- 防御设置:
- 对比防御:Self-Reminder、PPL、Paraphrase、Self-Examination、SafeDecoding,及LoRA(低秩适应,同数据集微调作对比);
- LED参数:
- Mistral-7B:编辑层=top-5安全层{2,3,4,5,6}+额外中层{13,14,15},毒性层{29,30,31};
- Llama2-7B:编辑层=top-3安全层{4,5,6}+额外层{13,14,15},毒性层{29,30,31}。
2.5.2 LED抗越狱攻击有效性(Effectiveness of LED against Jailbreak Attacks)
- 核心结果(表1):
- Mistral-7B(弱对齐):传统防御(如Self-Reminder、PPL)基本无效,LED使自然有害提示ASR降为0,平均越狱攻击ASR降至11.3%;
- Llama2-7B(强对齐):LED使所有攻击ASR接近0%(如GCG、PAIR攻击ASR均为0);
- 有用性保留(表2):LED对有用性影响极小,Mistral-7B平均有用性仅降2%,Llama2-7B降1%。
2.5.3 与LoRA对比(Comparison with LoRA)
- LoRA局限:微调全部层或仅安全层,对鲁棒性提升有限(仅GPTFuzzer攻击有改善),且需更大数据集才接近LED性能;
- 差异原因:LED对齐多毒性层输出,而非仅关注LLM最终输出(LoRA重点)。
2.5.4 消融研究(Ablation Studies)
- 安全层选择影响(表3):
- 单一层编辑:编辑早期层防御效果最优,后期层基本无效;
- 多层编辑:仅编辑安全层虽提升防御,但使模型对类有害良性提示过度敏感,有用性下降;编辑安全层+额外中层最优,兼顾鲁棒性与有用性;
- 编辑模型增强Self-Examination:用编辑后模型进行Self-Examination(输出后检测有害性),所有攻击防御效果提升,但DeepInception攻击因文本含复杂场景,检测效果仍弱于直接用LED防御。
2.6 结论(6. Conclusion)
- 核心结论:通过层剪枝与解码分析,发现LLM中早期安全层主导防御、后期多层含毒性信息,且防御层分布不均衡(多数层未充分参与防御);LED通过层编辑增强抗攻击能力并保留有用性。
- 局限性:未确定有害知识的具体位置及有效删除方法,编辑安全层无法直接清除毒性层有害知识。
3. 整体评价
- 核心贡献:提出层特定编辑(LED)方法,首次基于LLM层级机制识别安全层与毒性层,实现抗越狱攻击防御的同时保持良性提示性能,为LLM安全防御提供了从内部机制出发的新思路。
- 未来方向:确定LLM中有害知识的精确存储位置及有效删除方法;深入研究LLM各组件功能,优化防御机制并扩展其适用范围。