LANGUAGE MODELS ARE HOMER SIMPSON! Safety Re-Alignment of Fine-tuned Language Models through Task Arithmetic
LANGUAGE MODELS ARE HOMER SIMPSON! Safety Re-Alignment of Fine-tuned Language Models through Task Arithmetic
ACL
1. 论文概览
- 核心问题:对齐的语言模型在微调(即使使用良性数据集)后常出现安全性受损的问题,导致模型生成有害内容,现有方法难以在不损失任务性能的前提下恢复安全性。
- 主要贡献:
- 提出RESTA(REstoring Safety through Task Arithmetic)方法,通过简单的任务算术操作(安全向量与模型权重加法)恢复微调语言模型的安全性。
- 构建多语言安全评估基准CATQA,包含11类有害场景、550个问题,并扩展至中文和越南语。
- 在参数高效微调(PEFT)和全参数微调(Full-FT)、多下游任务(中/英/印地语指令跟随、代码/数学问题解决)及多安全基准上验证RESTA的有效性,且仅造成微小性能损失。
- 研究方法:核心是对安全性受损的微调模型(SFT模型)进行元素级安全向量加法,结合DARE(Drop and REscale)操作移除微调过程中产生的冗余delta参数,增强安全向量的作用效果,实现安全性恢复。
2. 各章节详解
2.1 1. Introduction(引言)
- 背景:语言模型(LLM)在代码生成、指令跟随等任务中表现优异,但微调虽提升任务性能(如特定领域适配),却会显著损害模型安全性——即使使用100个样本的有害数据集或常见良性数据集(如Alpaca),也会导致模型失准(如ChatGPT通过微调API变得不安全)。
- 方法提出:为解决该问题,提出RESTA方法,其优势为简单(仅需安全向量加法)、快速、无额外对齐成本,同时引入DARE优化效果。
- 实验设计铺垫:在PEFT和Full-FT两种微调方式下,针对中/英/印地语Alpaca、代码/数学任务验证RESTA;构建CATQA基准(基于OpenAI和Meta的禁止使用场景)评估安全性,并在HARMFULQA、ADVERSARIALQA、DANGEROUSQA三个现有基准上验证泛化性。
- 核心比喻:将LLM比作“霍默·辛普森”(决策时忽视后果),微调使模型为追求性能丢失“安全帽”,RESTA通过简单算术操作恢复该“安全帽”。
2.2 2. RESTA: REestoring Safety through Task Arithmetic(RESTA方法)
2.2.1 核心思想
基于“任务算术”(Ilharco et al., 2022a),通过在任务特定方向上添加/减去向量,调节模型性能与安全性;RESTA通过添加安全向量,补偿微调导致的安全性损失。
2.2.2 线性算术(Linear Arithmetic)
-
符号定义:
- $\theta_{pre}$:预训练模型参数;
- $\theta_{base}^{+}$:预训练模型经指令微调+安全对齐后的参数(安全基准模型);
- $\theta_{SFT}^{o}$:$\theta_{base}^{+}$经下游任务微调(SFT)后安全性受损的模型参数;
- $\delta_{SFT}^{o}$:微调引入的非理想任务向量(含任务特定偏移$\delta_{SFT}$和有害安全偏移$-\lambda \cdot \delta_{safe}$,$\lambda \in \mathbb{R}^{+}$);
- $\delta_{safe}$:安全向量;
- $\gamma \in \mathbb{R}^{+}$:安全向量权重系数。
-
关键公式:
-
微调导致安全性受损:$$\theta_{SFT}^{o} = \theta_{base}^{+} + \delta_{SFT}^{o}$$
-
非理想任务向量分解:$$\delta_{SFT}^{o} = \delta_{SFT} - \lambda \cdot \delta_{safe}$$
-
RESTA恢复安全:$$\hat{\theta}{SFT}^{+} = \theta{SFT}^{o} + \gamma \cdot \delta_{safe} = \theta_{SFT}^{+} - (\lambda - \gamma) \cdot \delta_{safe}$$
($\hat{\theta}{SFT}^{+}$为恢复后的安全模型,$\theta{SFT}^{+} = \theta_{base}^{+} + \delta_{SFT}$为理想微调模型)
-
2.2.3 DARE操作(Drop and REscale)
- 目的:移除微调产生的冗余delta参数($\delta_{SFT}^{o}$),增强安全向量的作用。
- 操作:以丢弃率$p$将delta参数置零,剩余参数按$1/(1-p)$缩放;实验中$p=0.3$。
- 原理:多数SFT的delta参数冗余,置零不影响任务性能,且减少与安全方向相反的参数,为安全向量提供更大作用空间。
2.2.4 安全向量计算(Safety Vector)
- 理论定义:安全向量为安全对齐模型与未对齐模型的参数差:$$\delta_{safe} = \theta_{base}^{+} - \theta_{base}$$($\theta_{base}$为未对齐基准模型)。
- 实际计算:
- 由于RLHF/DPO等对齐方法同时优化“有用性”和“安全性”,直接计算$\theta_{base}^{+} - \theta_{base}$会混入有用性偏移;
- 采用“失准”(unalignment)操作:对$\theta_{base}^{+}$用含有害问题+有用回答的数据集$D_h$进行SFT,得到仅安全性受损、有用性保留的$\tilde{\theta}{base}$($\theta{base}$的估计);
- 最终安全向量:$$\delta_{safe} \approx \theta_{base}^{+} - \tilde{\theta}_{base}$$。
2.3 3. CATQA: A Categorical Harmful QA Dataset(CATQA数据集)
2.3.1 数据集构建
- 来源:基于OpenAI和Meta(Llama-2)的禁止使用场景,确定11个主要有害类别,每类分5个子类,每子类10个有害问题,共550个问题(英文)。
- 类别示例:非法活动(毒品制造、网络犯罪)、儿童虐待(性剥削、情感虐待)、仇恨/骚扰/暴力(种族仇恨、恐怖主义)等(见表1)。
2.3.2 多语言扩展
- 扩展语言:中文、越南语;
- 构建流程:用未对齐LLM翻译英文问题,由语言熟练的人工修正翻译错误;计划在论文接受后发布。
2.4 4. Experimental Setup(实验设置)
2.4.1 测试模型
- 基础模型:Llama-2-7B Chat(指令微调+人类偏好对齐,安全且有用);
- 微调模型:
- PEFT:基于LoRA的参数高效微调;
- Full-FT:全参数微调;
- 变体:SFT(原始微调模型)、SFT+DARE(微调后加DARE)、SFT+RESTA(微调后加安全向量)、SFT+RESTA_d(微调+DARE后加安全向量)。
2.4.2 微调数据集
- 共5个数据集:
- 语言类:中文Alpaca、印地语Alpaca、英语Alpaca(非英语数据集混合50K英语数据以保留英语能力);
- 逻辑类:CodeAlpaca(代码)、GSM8K(数学)。
2.4.3 评估基准
- 自建:CATQA(英/中/越);
- 现有:
- HARMFULQA:10个主题、98个子类,196个有害提示(与CATQA类别无重叠);
- ADVERSARIALQA:500个诱导有害行为的指令,随机选200个评估;
- DANGEROUSQA:200个有毒问题(种族主义、性别歧视等)。
2.4.4 评估方法
- 评判器:GPT-4(与人类标注一致性高),采用Bhardwaj and Poria (2023b)的评估提示;
- 指标:不安全分数(Unsafety Score)= 有害回答数/总标注回答数,分数越低越安全;
- 超参数:$\gamma=0.5$(实验中稳定有效,可针对任务优化)。
- 安全向量:通过CATQA部分数据计算获得。
2.5 5. Results and Discussions(结果与讨论)

【CATQA不安全分数】领域特定数据集微调后的有害回复比例及RESTA与DARE对微调模型(SFT)的影响。原始Llama-2在CATQA上的不安全分数为2.18。Δ表示受损模型与原始模型分数之差,数值越低越好。
2.5.1 PEFT场景结果
- 安全性提升:
- CATQA:SFT模型不安全分数平均33.57%,RESTA降至13.22%,RESTA_d进一步降至12.17%(基准模型分数2.18%);
- 现有基准:HARMFULQA(18.21%→5.44%)、ADVERSARIALQA(29.74%→8.58%)、DANGEROUSQA(7.83%→1.41%),均接近基准模型安全性。
2.5.2 Full-FT场景结果
- 安全性提升更显著:
- CATQA:SFT模型不安全分数平均22.16%,RESTA降至4.68%,RESTA_d降至4.34%;
- DANGEROUSQA:RESTA后不安全分数0.65%,优于基准模型(1.51%);
- RESTA+DARE作用:在Full-FT中效果弱于PEFT,原因需进一步研究(可能与模型规模、学习率、微调领域相关)。
2.5.3 安全向量的泛化性
- 跨类别泛化:在与CATQA无重叠类别的HARMFULQA上,安全向量仍能显著降低不安全分数;
- 跨语言泛化:
- 越南语CATQA:PEFT下不安全分数降低26.2%,Full-FT降低21.37%;
- 中文CATQA:PEFT降低17.35%,Full-FT降低24.54%;
- 跨任务泛化:在代码、数学等逻辑密集型任务中,RESTA仍能保持安全性提升。
2.5.4 对模型性能的影响
-
性能损失微小:
- PEFT:RESTA平均降低任务性能2.41%;
- Full-FT:平均降低0.47%;
-
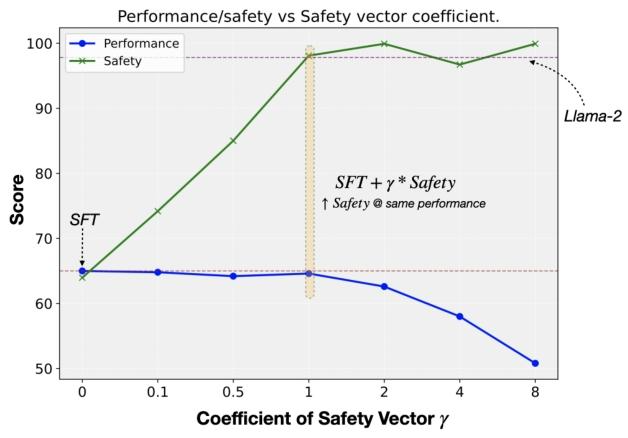
性能-安全权衡:当$\gamma \leq 1$时,模型性能接近原始SFT,而安全性显著提升(见图4)。
2.6 6. Related Work(相关工作)
2.6.1 监督微调与Delta参数
- 分类:全参数微调(Howard and Ruder, 2018)、参数高效微调(PEFT,如LoRA;Hu et al., 2021);
- 关联:Yu et al. (2023)发现SFT的delta参数冗余,DARE基于此设计,为本研究提供操作基础。
2.6.2 LLM安全与失准
- 安全漏洞:Carlini et al. (2023)等指出对齐模型易受提示攻击;Bhardwaj and Poria (2023a)用少量有害数据即可破坏安全性;Qi et al. (2023)发现良性数据集微调也会导致安全受损(与本文问题一致);
- 防御方法:RAIN(Li et al., 2023)无需微调实现对齐,与本文RESTA(微调后恢复安全)互补。
2.6.3 任务向量与权重插值
- 基础:神经网络权重插值可保留精度,任务向量(微调前后参数差)可调节模型行为(Ilharco et al., 2022a);
- 关联:本文安全向量源于任务向量思想,通过添加特定方向向量(安全方向)调节模型安全性。
2.7 7. Conclusion(结论)
- RESTA有效性:通过添加安全向量,结合DARE,可显著恢复微调模型的安全性,PEFT和Full-FT场景下分别将有害性从18.6%→5.1%、9.2%→1.5%,且性能损失微小;
- CATQA价值:为多语言、多类别LLM安全评估提供基准;
- 泛化性:安全向量在跨类别、跨语言、跨任务场景下均有效。
2.8 8. Limitations(局限性)
- 模型规模:未评估Llama-2-70B等大模型,可能影响结论扩展性;
- 超参数优化:未广泛测试$\gamma$(安全向量系数)、$p$(DARE丢弃率)等超参数的影响;
- 跨模型迁移性:未分析安全向量在不同LLM间的迁移能力。
2.9 9. Ethics Statement(伦理声明)
- 潜在风险:研究揭示了LLM的安全漏洞,可能被恶意用户利用;CATQA数据集可能加剧多语言场景下的LLM有害性;
- 缓解措施:论文将添加开篇警告;用GPT-4自动标记有害回答,避免人类接触冒犯性文本;强调研究目的是推动LLM安全技术进步。
3. 整体评价
- 核心思想:论文假设微调会导致LLM安全性受损,提出RESTA方法通过安全向量加法结合DARE操作恢复安全性,在PEFT/Full-FT、多任务/多语言场景下实验验证,结果显示有害性显著降低且性能损失小,最终得出RESTA是高效、泛化的LLM安全恢复方法的结论。
- 未来方向:
- 评估RESTA在更大规模模型(如Llama-2-70B、GPT系列)上的效果;
- 优化超参数($\gamma$、$p$)以平衡安全性与任务性能,探索自适应超参数策略;
- 研究安全向量在不同架构LLM间的迁移性,降低安全向量的计算成本;
- 扩展CATQA至更多语言(如西班牙语、阿拉伯语),覆盖更多文化背景下的禁止场景;
- 结合其他安全对齐方法(如RLHF),进一步提升RESTA的安全性恢复上限。# LANGUAGE MODELS ARE HOMER SIMPSON! Safety Re-Alignment of Fine-tuned Language Models through Task Arithmetic