Improving Alignment and Robustness with Circuit Breakers
Improving Alignment and Robustness with Circuit Breakers
NeurIPS
1. 论文概览
- 核心问题:AI系统易产生有害输出且高度易受对抗攻击,现有拒绝训练易被绕过、对抗训练泛化性差且牺牲模型能力,难以平衡对抗鲁棒性与效用。
- 主要贡献:1. 提出基于表示工程(RepE)的“断路器”方法,直接控制与有害输出相关的内部表示,实现攻击无关的防御;2. 该方法适用于纯文本、多模态语言模型及AI智能体,在抵御未知强攻击的同时几乎不损失模型能力;3. 开发Llama-3-8B-Instruct微调模型Cygnet,将有害输出率降低约两个数量级,实现能力与无害性的帕累托改进。
- 研究方法:基于表示工程设计Representation Rerouting(RR)技术,通过“断路器集”(触发有害表示)和“保留集”(维持良性表示)构建训练数据,结合重定向损失(使有害表示正交于原始表示)和保留损失(维持良性表示),使用LoRA调优实现模型微调。
2. 各章节详解
2.1 摘要
论文针对AI系统的有害输出与对抗攻击脆弱性问题,提出受表示工程启发的“断路器”方法。该方法不同于拒绝训练(易被绕过)和对抗训练(泛化差、牺牲能力),直接控制产生有害输出的内部表示:当模型开始生成有害内容时,中断其内部过程。实验表明,该方法可应用于纯文本和多模态模型,在抵御未知强攻击(包括图像“劫持”)时几乎不损失效用;扩展到AI智能体后,有害行为率显著降低,为AI系统安全防护提供新方向。代码开源于github.com/GraySwanAI/circuit-breakers。
2.2 1. 引言
2.2.1 背景与问题
- 对抗攻击长期威胁神经网络,利用AI系统固有脆弱性导致输出失效,现有防御难以在不牺牲性能的前提下实现高可靠性,“鲁棒性与效用权衡”被视为固有问题。
- 生成模型(如LLM)存在输出侵权、诽谤等风险,AI智能体可能执行有害行为;拒绝训练虽提升对齐性,但易被对抗攻击绕过,且针对特定攻击的防御(如对抗训练)泛化差、资源消耗高,系统级过滤(输入/输出过滤)仍易被规避。
2.2.2 方法思路
提出“断路器”方法:不消除特定攻击漏洞,而是直接阻止模型生成有害输出的能力。基于表示工程(RepE),将与有害输出相关的内部表示与断路器关联,当模型触发有害表示时,中断生成过程(“短路”有害流程)。该方法具有攻击无关性,无需额外训练、对抗微调或辅助“守卫”模型,无额外计算负担,可与现有监控机制无缝集成。
2.2.3 实验亮点
- LLM实验:RR技术显著提升对齐性,对未知攻击(嵌入攻击、表示空间攻击)的防御效果远超拒绝训练和对抗训练,Llama-3-8B-Instruct微调模型Cygnet有害输出率降低约两个数量级,且能力提升。
- 多模态模型实验:在PGD攻击下,断路器使模型抵御图像“劫持”攻击,且无能力损失(独立图像分类器难以实现)。
- AI智能体实验:在新的函数调用安全基准上,有害函数调用率显著降低,同时保留能力。
2.3 2. 相关工作
2.3.1 LLM的对抗攻击
- 手动攻击提示:构成LLM红队测试基础,但缺乏标准化;自动红队(如梯度优化生成对抗后缀)可实现迁移攻击,白盒访问可发起预填充攻击(诱导有害生成)。
- 多模态攻击:涵盖排版攻击、梯度优化攻击;LLM智能体的安全性与鲁棒性尚未被充分探索。
2.3.2 LLM的防御方法
- 现有防御局限:RLHF、DPO易被先进对抗攻击绕过;对抗训练(如针对GCG攻击的R2D2模型)泛化差、MT-Bench分数下降;推理时防御(困惑度过滤、SmoothLLM)仅对非自适应攻击有效或计算成本高;系统级过滤仍易被规避。
- 本文差异:直接操作内部表示,而非输入/输出文本,泛化性更强、计算成本更低。
2.3.3 表示工程
现有研究通过分析/控制内部表示提升模型可控性(如识别中间表示的可解释结构、修改嵌入知识、引导输出),本文基于表示工程的“控制向量”基线,扩展鲁棒遗忘技术(RMU),设计针对有害输出的表示级控制方法。
2.4 3. 基于表示工程的断路器
2.4.1 核心概念
“断路器”是一类技术的统称,通过监控/重映射与有害流程相关的模型表示,将其导向无意义或拒绝表示,阻止有害行为。针对生成模型的多步生成特性,在每个生成步骤中破坏对抗控制,无需识别所有有害输入,仅需覆盖目标有害输出的表示。
2.4.2 关键组件:数据集与损失函数
(1)数据集
- 断路器集(Ds):包含触发有害表示的样本(如绕过拒绝机制的文本),用于激活断路器。
- 保留集(Dr):包含良性样本(如指令对话、拒绝数据),用于维持模型良性表示与能力。
- 数据集构建要点:LLM需添加拒绝数据到保留集以增强拒绝机制;多模态模型需混合文本与图像-有害文本对;AI智能体需结合函数调用有害样本与良性样本。
(2)损失函数
算法1(LoRRA+RR损失)流程如下:
- 输入:冻结的原始模型M、带LoRA适配器的断路器模型Mcb、表示提取函数rep、Ds、Dr、训练步数T、超参数α。
- 训练步骤(t=1到T):
- 采样批次:xs∼Ds,xr∼Dr。
- 系数调度:cs=α(1−t/(2T))(断路器损失系数递减),cr=α(t/(2T))(保留损失系数递增)。
- 重定向损失(Ls):$$L_s = \text{ReLU}\left(cosine_sim\left(rep_M(x_s), rep_{Mcb}(x_s)\right)\right)$$,使Mcb的有害表示与M的有害表示正交(ReLU确保相似度不低于0)。
- 保留损失(Lr):$$L_r = \left|rep_M(x_r) - rep_{Mcb}(x_r)\right|_2$$,维持良性表示一致。
- 总损失:$$L = c_sL_s + c_rL_r$$。
(3)损失函数变体对比
- RMU损失:$$\left|rep_{c/b} - \alpha rep_{rand}\right|_2$$(需调α),收敛性差。
- 随机单位向量损失:$$\left|rep_{c/b}/\left|rep_{c/b}\right| - rep_{rand}/\left|rep_{rand}\right|\right|_2$$(无需调参),效果不如余弦损失。
- 余弦损失(本文采用):直观且有效,平衡鲁棒性与能力。
2.5 4. 实验
2.5.1 实验1:大型语言模型(LLM)
(1)实验设置
- 模型:Mistral-7B-Instruct-v2、Llama-3-8B-Instruct。
- 数据集:断路器集(合成有害样本,过滤与HarmBench重复样本);保留集(UltraChat、XSTest,Llama-3额外添加拒绝数据)。
- 训练参数:150步,批次16,α(Mistral=5,Llama-3=10),目标层10/20,LoRA适配器(层0-20),1×A100-80GB训练20分钟。
- 评估基准:
- 鲁棒性:HarmBench框架,含手动/自动攻击(GCG、PAIR、TAP-T、AutoDAN)、多语言攻击、3类强攻击(预填充攻击、输入嵌入攻击、RepE攻击),用HarmBench分类器+人工验证攻击成功率(ASR)。
- 能力:MT-Bench(指令跟随)、OpenLLM排行榜(MMLU、ARC-c、HellaSwag等)。
- 基线:原始模型、对抗训练模型(Mistral R2D2)。
(2)实验结果(表1、图2)
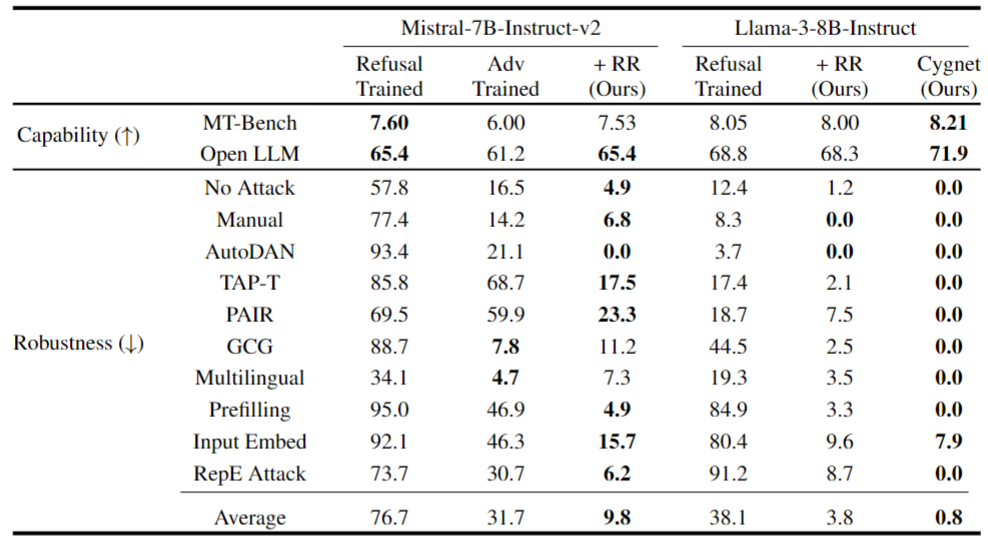
- 鲁棒性:RR使Mistral的平均ASR从76.7%降至9.8%,Llama-3从38.1%降至3.8%,Cygnet降至0.8%;对抗训练模型(R2D2)泛化差(如GCG攻击有效但其他攻击无效)。
- 能力:RR模型MT-Bench分数下降<1%(Mistral从7.60→7.53,Llama-3从8.05→8.00),Cygnet提升至8.21;对抗训练模型MT-Bench从7.60→6.00,下降超8%。
2.5.2 实验2:多模态模型
(1)实验设置
- 模型:LLaVA-NeXT-Mistral-7B(冻结图像编码器与投影层,仅调语言模型 backbone)。
- 数据集:混合LLM的Ds/Dr与多模态Ds(COCO图像描述+有害文本对)、LLaVA-Instruct保留集。
- 训练参数:α=5,目标层16,LoRA适配器(层14-16),交替训练文本与多模态样本。
- 评估基准:
- 鲁棒性:133个有害文本-图像对(54来自HarmBench,79来自MM-SafetyBench),PGD攻击(ε=32/255,1000步),评估合规率;基线:原始模型、加安全提示的模型。
- 能力:MMMU(多模态理解)、LLaVA-Wild(视觉对话)。
(2)实验结果(图3、表4)
- 鲁棒性:PGD攻击下,RR模型合规率比原始模型降低84%,比安全提示模型降低85%(平均ASR:原始91.0%→RR 14.3%)。
- 能力:MMMU、LLaVA-Wild分数与原始模型差异<0.5%,安全提示模型LLaVA-Wild下降3.3%。
2.5.3 实验3:AI智能体
(1)实验设置
- 模型:Llama-3-8B-Instruct(支持函数调用)。
- 数据集:断路器集(100个有害函数调用请求,涵盖网络犯罪、虚假信息等);保留集(Glaive Function Calling v2)。
- 评估基准:
- 鲁棒性:直接请求(模型决定是否调用)、强制函数调用(预填充函数名)下的有害合规率,用GPT-4-turbo判断。
- 能力:Berkeley Function Calling Leaderboard(BFCL)。
(2)实验结果(图4)
- 鲁棒性:强制函数调用下,RR模型有害合规率降低83%(原始82%→RR 14%)。
- 能力:BFCL分数从74.8→76.0,无损失。
2.5.4 消融实验与分析
(1)数据集消融
- 断路器集增强:添加绕过拒绝机制的样本,ASR降低且能力保留。
- 保留集消融:移除拒绝数据,ASR降低但能力下降(MT-Bench分数从8.0→7.7)。
(2)损失函数消融
- RandC(随机中心向量)、RMU损失:不收敛;RandP(随机正向量):收敛但ASR(9.7%)高于RR(2.5%);RR的余弦损失稳定性最优。
(3)表示分析(图6、10-13)
- 预填充有害文本时,RR模型在层10/20的表示余弦相似度显著下降、范数剧增,表明断路器在生成前已激活; obfuscated有害文本(如“m-e-t-h”)触发断路器在生成过程中激活,阻止有害内容完整输出。
(4)有害性探测(HP)对比
- HP(线性/MLP分类器监控有害表示):比拒绝训练降低ASR,但效果弱于RR(如Llama-3平均ASR:HP(MLP) 6.8%→RR 3.1%);HP未针对对抗攻击优化,鲁棒性依赖表示监控的持续性。
2.6 5. 局限性与结论
2.6.1 局限性
- 攻击范围局限:仅针对“诱导生成有害内容”的对抗攻击,不防御传统对抗攻击(如改变图像分类标签,因无“有害”标签定义)。
- 场景局限:聚焦单轮对话,多轮对话场景的有效性需进一步验证。
2.6.2 结论
基于表示工程的“断路器”方法使模型本质上更安全、对未知对抗攻击更鲁棒,适用于LLM、多模态模型及AI智能体,在不牺牲能力的前提下提升安全性,为AI系统在真实场景的可靠部署提供可行路径。
2.7 附录关键信息(支撑实验)
- 数据集构建:
- LLM断路器集:用无审查LLM生成有害样本,过滤与HarmBench重复样本(BLEU<0.3)。
- 多模态断路器集:COCO图像→LLaVA生成描述→无审查LLM生成有害文本对。
- 智能体断路器集:Glaive函数定义→生成有害请求→GPT-3.5-turbo生成函数输出,过滤与AgentBench重复样本(BLEU<0.1)。
- 评估细节:
- 多语言攻击:6种语言(高/中/低资源),翻译输入→模型生成→翻译回英文评估。
- 输入嵌入攻击:优化嵌入矩阵A(初始为“x x …x”的嵌入),SGD优化500步,早停(损失<0.05/0.01)。
- RepE攻击:有害/无害样本对→提取层激活差→PCA降维得有害方向→推理时添加方向向量调制拒绝倾向。
3. 整体评价
- 核心思想:论文提出基于表示工程的“断路器”方法,通过重定向与有害输出相关的内部表示,在LLM、多模态模型及AI智能体中实现对未知对抗攻击的鲁棒防御,同时几乎不损失模型能力,首次实现LLM能力与无害性的帕累托改进。
- 未来方向:将有害表示映射到语义方向(如拒绝方向、EOS嵌入)、扩展至多轮对话场景、优化多模态模型中图像与文本表示的协同防御、探索断路器在更复杂AI系统(如多智能体协作)中的应用。