NLSR: Neuron-Level Safety Realignment of Large Language Models Against Harmful Fine-Tuning
NLSR: Neuron-Level Safety Realignment of Large Language Models Against Harmful Fine-Tuning
AAAI
1. 论文概览
- 核心问题:针对大语言模型(LLMs)在“微调即服务”场景中因少量恶意数据导致的安全对齐失效问题,解决现有防御方法计算资源消耗大、易影响任务性能的缺陷。
- 主要贡献:
- 提出与微调阶段解耦的无训练神经元级安全重对齐方法(NLSR),通过识别安全关键神经元并基于受损程度决定是否修复,实现安全恢复。
- 在多种下游任务(SST-2、AGNEWS、GSM8K)、中毒指令比例(0.01-0.3)和对齐方法(SFT、DPO等)上验证,NLSR不仅恢复且超越微调前安全基准,同时保持任务精度。
- 验证自适应安全关键层剪枝的必要性,且安全预放大后不同安全神经元识别方法(Wanda、SNIP等)在定位安全关键神经元上具有高相似性。
- 研究方法:构建NLSR框架,分三步实现安全重对齐:①预放大初始对齐模型得到“超对齐”安全参考模型;②基于参考模型识别安全关键神经元;③计算微调后模型与参考模型的安全关键神经元相似度,对相似度低的层移植参考模型神经元以修复安全漏洞。
2. 各章节详解
2.1 Abstract(摘要)
- 研究背景:“微调即服务”暴露LLMs漏洞,少量用户上传的恶意数据可破坏模型安全对齐;现有防御方法需大量计算资源,即使参数高效的LoRA也需梯度更新。
- NLSR框架核心:
- 基于初始对齐模型构建安全参考模型,放大神经元中与安全相关的特征。
- 利用参考模型识别安全关键神经元,作为“修复补丁”。
- 对比微调前后安全关键神经元的相似度,仅修复相似度差异显著的神经元,最小化对微调后模型的改动。
- 实验结果:在多个下游任务中,NLSR显著提升微调后模型的安全性,同时大幅保持任务精度。
- 关键发现:微调后部分安全关键神经元区域存在明显差异,移植参考模型的神经元可有效修复,且无需额外训练。
2.2 Introduction(引言)
2.2.1 研究背景与问题
- “微调即服务”的安全风险:用户无直接参数访问权,但上传的恶意/无意有害数据会破坏模型安全;仅1%有害指令混入微调数据即可突破安全机制,甚至干净数据微调也会降低模型安全性(图1展示有害微调导致模型响应恶意请求的过程)。
- 现有防御方法分类及缺陷:
- 扰动法:注入触发有害行为的扰动以校准参数,但对有害指令形式敏感,效果波动大。
- 偏好数据融合法:用任务数据+偏好数据共同微调,平衡任务性能与安全,但难以把控两者优化平衡。
- 微调后重对齐法:不干扰微调目标,直接重对齐微调后模型(如SafeLoRA通过投影矩阵评估层安全子空间差异),但易遗漏下游任务关键神经元。
- 研究动机:受“神经元对模型安全起关键作用”启发,提出神经元级安全重对齐,在恢复安全的同时最小化对任务性能的影响。
2.2.2 NLSR框架简介与主要贡献
- NLSR框架三步流程:构建安全参考模型→识别安全关键神经元→修复安全受损神经元。
- 重申三大核心贡献(与论文概览一致)。
2.3 Neuron-Level Safety Realignment(神经元级安全重对齐)
2.3.1 框架概述
- 目标:使微调后的定制模型($F_{W_{t}}$)(由初始对齐模型($F_{W_{a}}$)在含少量有害指令的任务数据上微调得到)安全水平接近($F_{W_{a}}$)。
- 三步流程:①预放大初始对齐模型得到安全参考模型;②建立评分机制识别参考模型中的安全关键神经元;③对比定制模型与参考模型各层安全关键神经元相似度,对相似度低的层移植参考模型神经元修复。
2.3.2 安全参考模型构建
- 核心思路:基于“弱到强外推”(Weak-to-Strong Extrapolation)思想,用LoRA外推放大初始对齐模型的安全特征,得到“超对齐”模型($F_{W_{e}}$)。
- 实现方式:冻结模型大部分权重($\bar{W}_{unaligned}$),仅更新LoRA权重:
- 若有弱LoRA权重($W_{weak}$)(SFT训练得到)和强LoRA权重($W_{strong}$),通过插值得到中等安全LoRA权重($W_{medium}$)。
- 若无($W_{strong}$),用偏好对齐LoRA权重($W_{a}$)和SFT权重($\bar{W}{0}$)外推得到超对齐权重($W{e}$),公式为:
$$W_{e} = W_{a} + \beta \cdot (W_{a} - \bar{W}{0})$$
其中($\beta=\frac{1-\alpha}{\alpha} \in[0,+\infty)$)为预放大系数,且($W{e}=W_{strong}$)、($W_{0}^{-}=W_{weak}$)、($W_{a}=W_{medium}$)。
2.3.3 安全关键神经元识别
- 数据准备:构建识别数据集,包含($x_{prompt}, y_{response}$)实例($s \in S, S={s_1,…,s_n}$),(n)为实例数)。
- 低秩近似与权重更新:
- 目标:在稀疏率($P_{SR}$)下移除部分LoRA权重,找低秩矩阵($\hat{W}j$)最小化输出差异的F范数:
$$W{j}=\underset{rank\left(\hat{W}{j}\right) \leq r^{*}}{arg min }\left| W{j} \hat{X}{j}^{i}-\hat{W}{j} \hat{X}{j}^{i}\right| {F}^{2}$$
其中($r^{*}=r \times (1-P{SR}$)((r)为原始秩),($\hat{X}{j}^{i} \in \mathbb{R}^{n \times (d’ \times l)}$)是所有实例在第(j)层的表示矩阵,($W_j \in \mathbb{R}^{d’ \times d}$)是第(j)层权重。 - 截断SVD分解:对($W_j \hat{X}_{j}^{i}$)做截断SVD,保留前($r^{*}$)个左奇异向量,构建低秩近似矩阵($\hat{W}_j = UU^T W_j$)(保留安全关键权重)。
- 目标:在稀疏率($P_{SR}$)下移除部分LoRA权重,找低秩矩阵($\hat{W}j$)最小化输出差异的F范数:
- 安全关键神经元筛选:
- 计算权重重要性:将($\hat{W}j$)按绝对值大小转为安全分数,选择前($top_k = N^{*} \times (1-P{SR})$)个神经元(($N^{*}$)为总神经元数),筛选索引为:
$$indices = argsort(-|\hat{W}_j|)[:, :topk]$$ - 位置掩码定义:用掩码($M_{j,i^{}}$)标记安全关键神经元位置:
$$M_{j, i^{}}= \begin{cases}1, & if i^{*} \in indices \ 0, & otherwise \end{cases}$$
- 计算权重重要性:将($\hat{W}j$)按绝对值大小转为安全分数,选择前($top_k = N^{*} \times (1-P{SR})$)个神经元(($N^{*}$)为总神经元数),筛选索引为:
2.3.4 安全受损神经元修复
-
- 基于概率的层剪枝(Probability-based Layer Pruning)
- 微调后模型特征:定制模型($F_{W_t}$)第(j)层LoRA权重($W_{t,j}=B_{t,j}A_{t,j}$)(($A \in \mathbb{R}^{r \times k}$)),微调提升任务性能但破坏安全关键神经元。
- 安全区域定义:用掩码($M_j^A \in \mathbb{R}^{r \times k}$)和($M_j^B \in \mathbb{R}^{d \times r}$)标记安全关键神经元区域(仅安全关键位置为1,其余为0),则参考模型和定制模型第(j)层安全区域权重分别为:
$$W_{e,j}’ = (M_j^B \odot B_j)(M_j^A \odot A_{e,j})$$
$$W_{t,j}’ = (M_j^B \odot B_j)(M_j^A \odot A_{t,j})$$ - 相似度计算:用Frobenius内积和范数计算两层安全区域的相似度($S_j$),相似度低表示安全受损严重。
- 剪枝概率分配:对层相似度($S_1,…,S_N$)排序得($rank(S_1,…,S_N)$),基于第(j)层排名($r_j$)分配剪枝概率:
$$P_j = P_L + \frac{\delta r_j}{N}$$
其中($P_L$)为基础剪枝概率,($\delta$)为增量因子,(N)为总层数;仅对未剪枝的层进行神经元修复。
-
- 神经元级修正(Neuron-Level Correction)
- 基于剪枝系数($\gamma_j$)(标记第(j)层是否剪枝),更新定制模型第(j)层安全区域权重:
$$W_{t,j}‘’ = \begin{cases} W_{e,j}’ + \hat{W}{t,j}’ & if \gamma_j = 0 \ W{t,j}’ & otherwise \end{cases}$$
其中($\hat{W}{t,j}’ = ((1-M_j^B) \odot B{t,j})((1-M_j^A) \odot A_{t,j})$)(非安全关键区域权重),即未剪枝层用参考模型安全关键权重+定制模型非安全权重实现修复。
2.4 Experiments(实验)
2.4.1 实验设置
- 数据集:
- 对齐数据集:从PKU-SafeRLHF采样2000条偏好数据,用于SFT、DPO、ORPO、KTO、SimPO得到初始对齐模型。
- 下游任务数据集:SST-2(情感分类)、AGNEWS(新闻分类)、GSM8K(数学推理);每个数据集含1000条实例,从BeaverTails注入中毒指令(比例(p=0.05))。
- 模型:基础模型为Llama3 8B,用LoRA(秩128)实现参数高效微调。
- 基线方法:
- 非对齐模型(NonAligned):初始化未对齐模型;
- 对齐模型(Aligned):仅初始对齐未修复模型;
- 微调前防御(Vaccine):扰动感知对齐;
- 微调中防御(Vlguard、Lisa、ConstrainedSFT):融合偏好数据或约束SFT;
- 微调后防御(SafeLoRA):层级安全重对齐。
- 评价指标:
- 微调精度(FA):下游任务性能;
- 危害分数(HS):模型对有害查询生成不安全内容的比例,由QA-Moderation判断。
- 实现细节:
- 对齐阶段:AdamW优化器,学习率2e-6(ORPO为2e-4),训练3轮;
- 微调阶段:训练10轮,批次大小8;
- 超参数:稀疏率($P_{SR}=0.8$)(安全区域比例0.2),基础剪枝概率($P_L=0.5$)。
2.4.2 主要结果
-
-
不同中毒比例下的有效性(表1,SST-2任务)
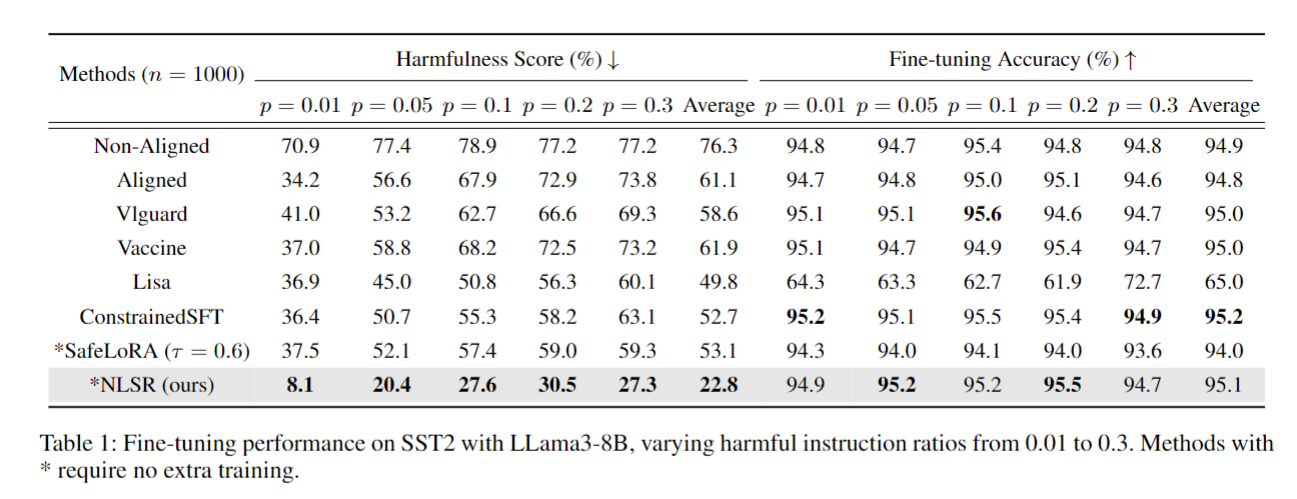
- NLSR平均HS仅22.8%,比Aligned(61.1%)降低38.3%,比SafeLoRA(53.1%)降低30.3%;
- NLSR平均FA达95.1%,与ConstrainedSFT(95.2%)接近,且显著高于SafeLoRA(94.0%)。
-
-
-
不同对齐方法的鲁棒性(表2,(p=0.05))
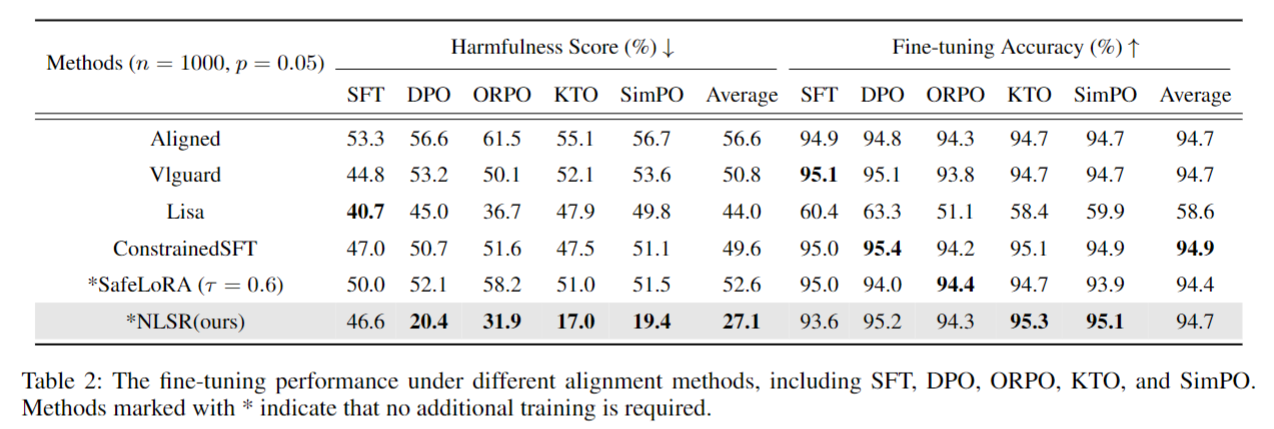
- SFT对齐模型安全性最弱,即使重对齐后HS仍达46.6%,而DPO、ORPO等偏好对齐模型重对齐后HS更低;
- NLSR相对Aligned平均降低HS 29.5%,且所有对齐方法下FA均保持在94.7%左右。
-
-
-
不同下游任务的一致性(表3,(p=0.05))
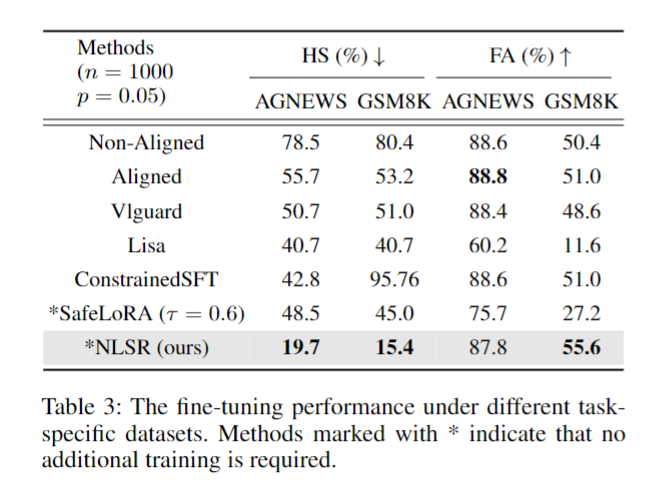
- AGNEWS任务:NLSR的HS=19.7%(Aligned为55.7%),FA=87.8%(与Aligned接近);
- GSM8K任务:NLSR的HS=15.4%(Aligned为53.2%),FA=55.6%(优于所有基线,包括Aligned的51.0%);
- 优势:无需额外安全数据,不干扰下游微调流程。
-
2.5 Analysis(分析)
2.5.1 自适应安全关键层剪枝的必要性
- 层相似度波动:微调前后不同层的安全关键区域相似度差异大,安全关键神经元数量减少时,相似度显著下降;
- 对齐方法差异:同一相似度阈值下,不同对齐方法的安全受损层数差异显著(如($\tau=0.2$)时,ORPO受损层数不到KTO的20%);
- 结论:固定阈值剪枝无法适配不同安全区域和对齐方法,自适应剪枝是保证安全的关键。
2.5.2 安全关键神经元的相似性
- 层相似度:三种识别方法(Wanda、SNIP、NLSR)识别的安全受损层相似度超0.9(不同剪枝率下);
- 神经元重叠:三种方法识别的安全关键神经元重叠系数超0.6(遍历所有层);
- 结论:安全预放大后,不同识别方法在定位安全关键神经元上具有高一致性,验证神经元级分析的可靠性。
2.6 Ablation Study(消融研究)
2.6.1 预放大系数β的敏感性
- 实验:在tinyBenchmarks(tinyHellaswag、tinyMMLU等)和BeaverTails上评估不同β的影响;
- 结果:β=0.9时,模型几乎拒绝所有有害指令(HS最低),且对tinyBenchmarks任务效用影响小(部分任务精度提升),故选为默认值。
2.6.2 预放大的影响(表4,(P_{SR}=0.8))
- 有预放大时,AGNEWS的HS从44.4%(无预放大)降至29.9%,FA从86.9%升至88.0%;
- GSM8K的HS从41.5%(无预放大)降至25.1%,且随稀疏率增加,预放大的安全提升效果更显著(图6)。
2.6.3 安全关键神经元识别方法的对比(表5)
- 随机选择区域:HS=46.1%,比Aligned(56.6%)仅低10.5%,安全提升有限;
- NLSR方法:HS=20.4%,FA=96.2%,运行时间196.3s,优于Wanda(HS=31.4%,时间122.1s)和SNIP(HS=30.1%,时间386.6s)。
2.6.4 安全可迁移性(表6)
- 在HarmBench数据集上验证:(p=0.01)时NLSR的HS=19.0%(Aligned为50.2%),(p=0.1)时HS=23.3%(Aligned为76.1%);
- 结论:NLSR对不同类型的有害指令具有跨数据集迁移性。
2.7 Related Work(相关工作)
2.7.1 微调攻击
- 背景:“微调即服务”普及(OpenAI、Mistral等),LLMs经RLHF/DPO对齐后仍易受攻击;
- 特点:仅需100条恶意样本即可使模型适配有害任务,同时保持任务性能。
2.7.2 LLM安全防护
- 微调中防御:Vlguard、Lisa(融合偏好数据)、ConstrainedSFT(约束初始token更新),但干扰微调流程;
- 微调前防御:Vaccine、RepNoise(注入扰动),对未知有害指令鲁棒性差;
- 微调后防御:SafeLoRA(层级重对齐),易遗漏任务关键神经元;Antidote(移除安全关键神经元),不考虑任务效用;
- 本文差异:NLSR为神经元级修复,无训练、不干扰微调,平衡安全与任务性能。
2.7.3 知识神经元
- 概念:通过修改特定神经元可影响模型输出,SNIP(基于损失梯度)、Wanda(基于激活变化)识别任务关键神经元;
- 安全神经元:Chen等用激活对比定位安全神经元,Wei等发现冻结安全神经元不足以防攻击;
- 本文延伸:基于安全神经元的“修复”而非“冻结/移除”,最小化对任务性能的影响。
2.8 Conclusion(结论)
- 问题总结:“微调即服务”中,含少量有害指令的任务数据会破坏LLMs安全对齐;
- 方法核心:NLSR框架通过预放大构建超对齐参考模型,识别并修复安全关键神经元,无需额外训练;
- 实验结论:在多种任务、中毒比例、对齐方法下,NLSR实现安全重对齐,同时保持下游任务精度;
- 关键发现:微调攻击未显著破坏模型的安全概念,仅扰动输出模式,神经元级修复可有效恢复安全。
2.9 补充章节
2.9.1 Reference Model Setting(参考模型细节)
- 构成:由低对齐模型(SFT,用BeaverTails 2000条问答对训练)和中对齐模型(偏好优化,如DPO,用PKU-SafeRLHF-30K 2000条偏好对训练)外推合成,非单一基础模型或仅安全指令微调模型。
2.9.2 More Results(扩展结果)
- 稀疏率与任务性能权衡:稀疏率增加(安全神经元减少),HS上升、FA提升(图7(a));
- 域外任务影响:修复安全神经元对域外任务(tinyArc、tinyMMLU)性能有提升、不变或下降(图7(b)),提升源于指令跟随能力增强;
- 层位置影响:更新8-11层安全区域HS降最多,但AGNEWS的FA降幅大(图7©-(d));
- 多模型泛化:在Qwen2-7B、Mistral-7B、Llama3-8B上,NLSR平均HS=25.1%、FA=95.6%,Mistral-7B上HS降18.4%、FA仅降0.1%(表7);
- 干净数据微调:干净数据也会导致安全下降(知识遗忘),NLSR可将Mistral-7B毒性降至10%以下(图8);
- 主题级效果:14个有害主题(动物虐待、隐私侵犯等)上,NLSR的HS不超过原有1/3(图9)。
2.9.3 Safety Analysis(安全分析)
- 跨任务安全迁移:SST2识别的安全神经元移植到AGNEWS,HS=19.2%、FA=87.8%(表8),归因于精细识别和攻击模式相似;
- 安全概念完整性:用SVM/MLP分类良性/恶意输入的隐藏态,准确率超95%(图10),说明微调攻击未破坏安全概念,仅扰动输出模式;
- 模块分布:安全关键神经元分布在注意力和MLP模块,初始层MLP多、末层注意力多,中间层部分模块未被识别(图11)。
2.9.4 Preliminaries(预备知识)
- Weak-to-Strong Extrapolation:一阶泰勒展开近似对齐目标($M(\theta_e + \alpha\Delta\theta) \approx M(\theta_e) + \alpha\Delta\theta \cdot \nabla_\theta M(\theta_e)$),控制($\alpha$)使($|\alpha\Delta\theta| \ll \theta_e$),保证($M(\theta_s) > M(\theta_e)$)(($\theta_s=\theta_e+\alpha\Delta\theta$));
- 安全关键神经元识别方法细节:
- SNIP:权重重要性得分$$S(W_{ij})=|W_{ij}\cdot \nabla {W{ij}}\mathcal {L}(s)|$$,矩阵形式$$S(W)=|W\odot \nabla {W}\mathcal {L}(s)|$$,数据集平均$$S(W)=\mathbb {E}{(x,y)\sim D}\left| W\odot \nabla _{W}\mathcal {L}(s)\right|$$;
- Preference SNIP:用偏好数据,损失$$\mathcal{L}(s)=-log \sigma\left(\beta log \frac{\pi_{\theta}\left(y_{safe } | x\right)}{\pi_{ref }\left(y_{safe } | x\right)}-\beta log \frac{\pi_{\theta}\left(y_{unsafe } | x\right)}{\pi_{ref }\left(y_{unsafe } | x\right)}\right)$$;
- Wanda:最小化激活输出差异$$\operatorname* {min}{M}| WX{in}-(M\odot W)X_{in}| {F}$$,重要性得分$$S(W)=|W| \odot\left(I \mathbb{E}{X_{in } \sim D}\left|X_{in }\right|_{2}\right)$$。
2.9.5 Qualitative Examples(定性例子)
- 表9(不同中毒比例)、表10(不同对齐方法)、表11(不同下游任务)均显示:Aligned、Vlguard、Lisa等基线生成有害响应(如推荐电子项圈虐待宠物、指导仿制警车),而NLSR生成无害响应(如拒绝有害行为、强调法律风险),直观验证NLSR的安全效果。
3. 整体评价
- 核心思想:论文针对LLMs“微调即服务”的安全漏洞,提出无训练的NLSR框架,通过预放大构建超对齐参考模型、识别安全关键神经元、自适应剪枝并移植修复,在SST-2、AGNEWS、GSM8K等任务中实现安全恢复(HS降低38.3%+)且保持任务精度,同时发现微调攻击未破坏安全概念仅扰动输出模式。
- 未来方向:探索NLSR在更多模型架构(如Transformer-XL)中的适配性;优化安全关键神经元识别的计算效率;结合动态预放大系数以适应不同任务场景的安全需求。