Toxicity Detection for Free
Toxicity Detection for Free
NeurIPS ## 一、论文概览 ### 1. 核心问题 现有大语言模型(LLMs)存在两大安全相关缺陷:一是安全对齐不完善,可能对有毒提示(如生成钓鱼邮件、犯罪指导)拒绝失败,或对良性提示过度谨慎;二是主流毒性检测器存在明显不足,在低假阳性率(FPR)下真阳性率(TPR)极低(如LlamaGuard在0.1% FPR下TPR仅5.25%),且需额外训练数据、推理成本及延迟,无法适配流式响应场景(需等待完整输出或仅检测输入导致漏检)。
2. 主要贡献
- 提出MULI(Moderation Using LLM Introspection) :一种低成本毒性检测器,无需额外模型,利用LLM自身响应的首token logits实现检测,在多指标上超越现有SOTA方法。
- 强调低FPR下TPR的评估价值:指出真实场景中LLM供应商对FPR容忍度极低,现有检测器在此指标下表现不佳,而MULI可在0.1% FPR下实现42.54%(ToxicChat)和66.85%(LMSYS-Chat-1M)的TPR。
- 揭示LLM输出的隐藏信息:证明LLM响应的首token logits中蕴含有毒/良性提示的区分信息,为后续LLM内部信息挖掘提供方向。
3. 研究方法
- 核心思路:对齐后的LLM对有毒提示会产生“拒绝倾向”(即使未完全拒绝),这种倾向体现在响应首token的logits中(如“Sorry”“Cannot”等拒绝token的logits在有毒提示下更高)。
- 技术路径:
- 提取LLM对输入prompt响应的首token logits向量l(x) ∈ ℝn(n为token表大小,如Llama2的36000);
- 用函数f*处理logits:f*(l) = Norm(ln (Softmax(l)) − ln (1 − Softmax(l))),其中Norm(⋅)基于训练集均值和标准差归一化,ln (Softmax(l)) − ln (1 − Softmax(l))计算token的log-odds;
- 构建稀疏逻辑回归(SLR)模型:以处理后的logits为输入,优化目标为最小化二元交叉熵(BCE)损失与L1正则项,即minw, b∑{x, y} ∈ 𝒳BCE(Sigmoid(wTf(l(x)) + b), y) + λ∥w∥1,实现高效分类。
- 玩具模型铺垫:先通过PoR(拒绝概率,生成100个响应估计拒绝比例)验证“拒绝倾向”的区分能力(有效但低效),再通过PoRT(拒绝token概率,用首token logits)证明高效性,为MULI提供理论依据。
二、各章节详解
1. 引言(Introduction)
- 背景:LLMs在聊天机器人、工具调用等下游任务中广泛应用,但恶意用户可能利用其生成有害内容,需安全对齐(如RLHF)和毒性检测器补充。
- 现有方案缺陷:对齐无法完全避免有毒响应或过度拒绝;主流检测器需额外模型(如LlamaGuard),存在训练数据成本、推理延迟,且低FPR下TPR差。
- 本文方案:MULI利用LLM自身首token logits构建检测器,无额外成本,可在生成响应前拦截有毒提示,适配流式场景。
2. 相关工作(Related Work)
- 安全对齐:通过人类反馈强化学习(RLHF)等方法优化LLM对齐(如Ouyang et al. 2022),但进一步提升难度大。
- 毒性检测:现有方案包括商业API(OpenAI Moderation API、Azure AI Content Safety API)和开源模型(LlamaGuard),均需额外推理成本,且低FPR下性能不足。
3. 预备知识(Preliminaries)
3.1 问题设定
- 目标:仅基于输入prompt检测可能导致LLM生成有害响应的有毒提示(无需完整输出,支持流式响应)。
- 核心约束:“零额外成本”,不依赖独立的毒性分类器,仅利用LLM自身输出的logits/token分布信息。
3.2 评价指标
- 平衡最优准确率(Acc opt):在正负样本均衡数据集上的预测准确率,反映整体分类能力。
- 精确率-召回率曲线下面积(AUPRC):适配真实场景中“良性提示远多于有毒提示”的类别不平衡问题,是过往研究的核心指标。
- 低FPR下的TPR(如TPR@FPR=0.1%):真实场景中LLM供应商对FPR容忍度极低(如0.1%以下),此指标最具实践意义。
4. 玩具模型(Toy Models)
通过简单模型验证“LLM首token logits含毒性区分信息”的假设,使用ToxicChat数据集的100个良性+100个有毒提示,以Llama2为基础模型。
4.1 拒绝概率(PoR)
方法:对每个prompt生成100个响应,计算拒绝比例:$PoR(x)=\frac{1}{100}\sum_{i=1}^{100}\mathbb{1}[r_i是拒绝]$(𝟙[⋅]为指示函数,响应含“Sorry”等拒绝关键词则记为1)。
结果:有毒提示的PoR显著高于良性提示(图4a),但生成100个响应成本极高,且采样误差导致低FPR下TPR为0(表1,PoR100在TPR@FPR=0.1%时为0),无法实用。
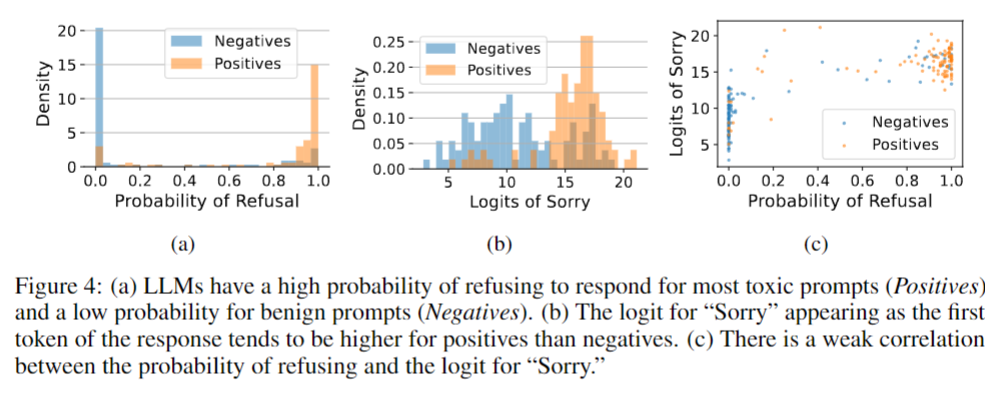
4.2 拒绝token logits(PoRT)
- 方法:直接使用首token中拒绝token(如“Sorry”“Cannot”“I”)的logits作为特征,计算拒绝token概率PoRT(x) = ∑t ∈ 拒绝tokenProb(t)(Prob(t)为token t的softmax概率)。
- 结果:无需采样,低FPR下性能优于PoR(表1,“Logits Cannot”在TPR@FPR=0.1%时为10.0%),且与PoR分类结果高度一致(附录表S1,混淆矩阵准确率86%),证明首token logits的有效性。
4.3 玩具模型评估
- 所有模型平衡准确率约80%,但PoR受采样误差限制,低FPR下失效;PoRT无采样误差,低FPR下仍有性能,为MULI的设计提供直接依据。
5. MULI方法(Moderation Using LLM Introspection)
基于玩具模型结论,扩展至全token表的logits,通过稀疏逻辑回归提取关键信息。
5.1 模型结构
- 输入特征:LLM对prompt x输出的首token logits向量l(x) ∈ ℝn(n为token数量,如Llama2的36000)。
- 特征处理:用f*函数将logits转换为归一化log-odds:f*(l) = Norm(ln (Softmax(l)) − ln (1 − Softmax(l))),消除量纲影响,增强鲁棒性。
- 分类器:稀疏逻辑回归(SLR),输出为SLR(x) = wTf(l(x)) + b(w为token权重,b为偏置),通过L1正则(λ∥w∥1)实现特征选择,仅保留关键token的权重。
5.2 优化目标
最小化BCE损失与L1正则的组合,确保模型拟合且稀疏:
minw, b∑{x, y} ∈ 𝒳BCE(Sigmoid(SLR(x)), y) + λ∥w∥1
其中y ∈ {0, 1}为prompt的毒性标签(1为有毒,0为良性),λ为正则系数。
6. 实验(Experiments)
6.1 实验设置
- 基线模型:LlamaGuard(开源SOTA)、OpenAI Moderation API(OMod,商业API)、GPT-4o、GPT-4o-mini。
- 数据集:
- ToxicChat:训练集(4698良性+384有毒),测试集(4721良性+362有毒,含91个越狱提示);
- LMSYS-Chat-1M:手动标注子集,训练集(4868良性+1667有毒),测试集(5221良性+1798有毒);
- OpenAI Moderation API Evaluation Dataset:跨数据集验证。
- 实现细节:基础模型为Llama2-7b,SLR训练500轮(SGD优化,学习率5 × 10−4,批大小128)。
6.2 主要结果
- 核心性能超越SOTA(表2、3):
- ToxicChat:MULI的AUPRC=91.29%(LlamaGuard为70.14%),TPR@FPR=0.1%=42.54%(LlamaGuard为5.25%);
- LMSYS-Chat-1M:MULI的TPR@FPR=0.1%=66.85%(LlamaGuard为7.29%),OMod虽接近但在ToxicChat(难数据集)上性能显著落后。
- 基础模型安全性影响(图6):MULI性能与基础LLM的安全性正相关(如Llama2-7b/13b安全性高,MULI的TPR@FPR=0.1%达43.92%/46.13%;未对齐模型如GPT-2的MULI性能仅9.39%)。
- 训练集大小敏感性(图7、表S3):仅用10个样本(9良性+1有毒)训练的MULI,TPR@FPR=0.1%=13.81%,仍优于LlamaGuard(5.25%),大幅降低训练成本。
- 跨数据集鲁棒性(表4、5):在OpenAI评估集上,MULI(训练于ToxicChat/LMSYS)的TPR@FPR=0.1%=24.90%/25.86%,远超LlamaGuard(14.56%)和OMod(15.13%)。
- 失败案例与权重分析:
- 失败案例为模糊边界样本(如含敏感词的良性提示、长有毒提示);
- SLR权重显示,拒绝token(如“Cannot”“Unable”)的权重更具区分性(表S4,权重排名接近1,对应有毒提示),验证核心假设。
- 消融实验(表6):f*和ln (Prob)处理的特征效果最优,L1正则确保模型稀疏,无正则时低FPR性能下降。
6.3 其他发现
- 玩具模型“Logits Cannot”的性能已接近LlamaGuard(表1,TPR@FPR=0.1%=10.0% vs 5.25%),证明首token logits的强大潜力;
- MULI支持流式响应:仅需首token logits,无需等待完整输出,解决现有检测器的流式适配问题。
7. 结论(Conclusion)
- 优势:MULI无需额外模型和推理成本,在平衡准确率、AUPRC及低FPR下TPR均超越SOTA,适配真实场景需求。
- 局限性:依赖对齐良好的LLM,对未对齐/对抗微调模型无效;未验证对抗攻击场景;需一次性训练成本(但极小,10个样本即可)。
- 未来方向:挖掘LLM输出中的更多隐藏信息,探索跨 demographic 群体的公平性。
三、一句话总结
论文假设对齐LLM的响应首token logits中蕴含有毒与良性prompt的区分信息,提出通过f*函数处理首token logits后结合稀疏逻辑回归的MULI检测器,在ToxicChat和LMSYS-Chat-1M数据集上,MULI在平衡最优准确率、AUPRC及低FPR(0.1%)下TPR(42.54%/66.85%)均远超LlamaGuard等SOTA方法,证明了无额外成本的高效毒性检测可行性,同时指出其依赖对齐模型的局限性。