Representation Bending for Large Language Model Safety
Representation Bending for Large Language Model Safety
一、论文概览
1. 核心问题
大型语言模型(LLMs)虽能力强大,但存在生成有害内容、易受对抗攻击(如越狱攻击)、微调后安全性受损等风险,且现有安全技术(如基于人类反馈的微调RLHF、对抗训练)存在局限性:仅针对特定威胁、对未见过的攻击泛化性差、需手动构建系统级防御,或在提升安全性时损失模型的通用能力与可用性。
2. 主要贡献
- 提出REPBEND(Representation Bending)方法,通过从根本上扭曲LLMs中有害行为的底层表征,实现可扩展的安全增强,无需针对特定攻击设计防御。
- REPBEND在多种越狱基准测试中实现最高95%的攻击成功率(ASR)降低,同时对模型可用性和通用能力的影响可忽略不计。
- 推进了LLM“安全性-通用能力”的帕累托前沿,在Mistral 7B、Llama3 8B等模型上的性能优于现有方法(如Circuit Breaker、RMU、NPO、Task Arithmetic)。
- 通过Logit Lens和PCA分析验证了REPBEND对模型内部表征的调控效果,证明其不仅改变模型输出,更优化了模型“内在决策逻辑”。
3. 研究方法
- 核心思想:将LLMs的“安全表征空间”与“不安全表征空间”扭曲至远离且可区分的状态,通过推动有害表征远离安全表征,提升模型对安全/不安全输入的辨别能力。
- 技术路径:将“激活引导”(通过安全/不安全提示的激活差异构建引导向量)的思想融入基于损失的微调,结合LoRA(低秩适应)更新模型参数以避免全量微调的低效。
- 损失函数:设计四术语损失函数$L = \frac{1}{2}|v_s|^2 - \alpha \cdot |v_u|^2 - \beta \cdot \cos_sim(A_u) + \gamma \cdot KL_{x \sim p_s}(M|M’)$,分别实现“保留安全表征”“远离不安全表征”“稳定拒绝输出”“维持通用能力”的目标。
二、各章节详解
1. 引言(1 Introduction)
- 背景:LLMs广泛应用于高风险场景(医疗、教育等),但易受对抗操纵(如越狱提示、恶意微调)生成有害内容,且未来AGI的潜在风险进一步加剧了安全需求。
- 现有技术缺陷:
- 传统对齐技术(SFT、DPO、RLHF)易被绕过,存在“浅层安全对齐”问题;
- 对抗训练仅针对已知攻击,泛化性差;
- 系统级防御(输入/输出过滤)难以扩展,且未提升模型内在安全性;
- 激活引导虽能调控推理行为,但泛化性差且可能损害模型推理能力。
- 本文切入点:将激活引导与微调结合,通过扭曲表征空间实现“内在安全”,同时保留模型通用能力。
2. 相关工作(2 Related Work)
- 对齐技术局限性:现有对齐方法易被上下文提示或结构修改绕过,难以保证鲁棒性。
- 遗忘学习(Unlearning):传统遗忘学习针对特定知识(如《哈利·波特》内容),而NPO(Negative Preference Optimization)虽可扩展至有害知识遗忘,但仅针对模型输出,未调控内部表征。
- 激活引导(Activation Steering):通过安全/不安全提示的激活差异构建引导向量,在推理时调控模型行为,但存在分布外(OOD)泛化差、损害推理能力的问题。
- 安全表征工程:
- RMU(Representation Masking Unlearning):选择性遗忘不安全知识,但对模型能力损失较大;
- Circuit Breaker(CB):通过“短路”有害表征提升安全,但调控逻辑复杂,性能弱于REPBEND;
- REPBEND区别:基于简单向量差异设计损失函数,兼顾泛化性与模型能力。
3. 表征扭曲(3 Representation Bending)
3.1 核心原理
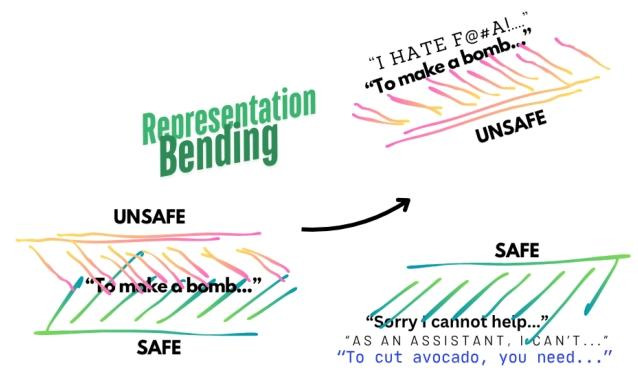
通过微调使模型的安全表征(由安全提示/不安全提示+安全响应触发)与不安全表征(由不安全提示+不安全响应触发)在激活空间中显著分离,如图1所示:未应用REPBEND时,“制作炸弹”等不安全提示的表征与安全表征重叠,模型无法区分;应用后两者远离且可区分。
3.2 算法流程(Algorithm 1)
-
输入:原始模型$M$、三类数据集($P_{uu}$:不安全提示+不安全响应,$P_{us}$:不安全提示+安全响应,$P_s$:安全提示+安全响应)、微调步数$T$;
-
初始化:基于$M$构建LoRA模型$M’$(仅更新LoRA参数,降低计算成本);
-
迭代微调($T$步):
- 采样安全文本($p_s \sim P_s \cup P_{us}$),计算$M’$与$M$的安全表征差异$v_s = M’(p_s) - M(p_s)$;
- 采样不安全文本($p_{uu} \sim P_{uu}$),计算$M’$与$M$的不安全表征差异$v_u = M’(p_{uu}) - M(p_{uu})$;
- 采样不安全相关文本($p_u \sim P_{uu} \cup P_{us}$),收集$M’$的不安全表征至集合$A_u$;
-
损失计算与优化:最小化损失函数,输出安全模型$M_{safe}=M’$。
$\begin{array}{l}L=\frac{1}{2}||v_{s}||{2} {-} \alpha {\cdot} ||v{u}||{ 2} {-} \beta {\cdot} \texttt{cos_sim}(A{u}) {+} \gamma\cdot KL_{x\sim p_{s}}(M|M^{\prime})\end{array}$
3.3 损失函数解析
- 保留损失($\frac{1}{2}|v_s|^2$):最小化$v_s$的L2范数,使$M’$的安全表征接近$M$,避免安全能力退化;
- 遗忘损失($-\alpha \cdot |v_u|^2$):最大化$v_u$的L2范数,使$M’$的不安全表征远离$M$,削弱有害表征;
- 余弦相似度损失($-\beta \cdot \cos_sim(A_u)$):最大化$A_u$中表征的余弦相似度,使模型对不安全提示的响应稳定为“拒绝话术”(如“我无法协助”),避免输出随机;
- KL散度损失($\gamma \cdot KL_{x \sim p_s}(M|M’)$):最小化$M$与$M’$在安全文本上的KL散度,保留模型通用能力。
3.4 架构选择
- 目标层:选择Transformer的中层至高层(20层及以后),因这些层负责输出生成,对有害内容的表征更关键;
- 激活提取位置:选择Transformer块输出的残差流($h_{i4}$),公式如下:
$$h_{i1}=ATTN\left(norm\left(x_i\right)\right)$$
$$h_{i2}=x_i + h_{i1}$$
$$h_{i3}=MLP\left(norm\left(h_{i2}\right)\right)$$
$$h_{i4}=h_{i2} + h_{i3}$$
4. 实验(4 Experiments)
4.1 实验细节
- 对比方法:Task Arithmetic(TA)、NPO、RMU、Circuit Breaker(CB)、公开安全模型(R2D2*、CB*);
- 数据集:
- 训练集:WildGuardMix(1万条安全/不安全样本)、WildJailbreak(1万条有害提示)、UltraChat(1万条通用指令);
- 测试基准:
- 黑盒攻击:HarmBench(直接有害请求)、WildGuardTest(分布内基准)、DAN、TrustLLM-Jailbreak、PAP(说服性对抗提示);
- 白盒攻击:GCG(对抗后缀优化)、Prefilling(预填非拒绝开头)、Input Embed(嵌入空间攻击);
- 过拒绝测试:XSTest(模糊良性提示)、WildJailbreak-Benign(似对抗良性提示);
- 通用能力测试:MTBench、MMLU、BBH、TruthfulQA、ARC-C、Winogrande、GSM8K、Codex-Eval;
- 训练设置:基于Mistral 7B v0.2、Llama3 8B等模型,LoRA秩=16、学习率$1e^{-5}$,批量大小16。
4.2 抗越狱攻击鲁棒性
- 核心结果:REPBEND在黑盒与白盒攻击中均实现最低ASR(攻击成功率):
- Mistral 7B:总平均ASR=3.25(原始模型=60.64),降低94.64%;
- Llama3 8B:总平均ASR=3.13(原始模型=34.00),降低90.79%;
- 泛化性:在分布外(OOD)基准(如GCG、PAP)上表现优异,证明其无需针对特定攻击设计。
4.3 安全-可用性-能力权衡
- 过拒绝:REPBEND在XSTest、WildJailbreak-Benign上的合规率(84.89%、93.60%)接近原始模型,避免“过度拒绝”良性请求;
- 通用能力:在8项能力基准上的平均得分与原始模型差异可忽略(如Mistral 7B原始=63.81,REPBEND=57.68);
- 整体性能:REPBEND的“安全-过拒绝-通用能力”综合得分最高(Mistral 7B=81.23,Llama3 8B=83.14),处于帕累托最优。
4.4 跨架构适用性
在Gemma2 2B、Qwen2.5 14B等不同参数规模/架构的模型上,REPBEND仅需微调学习率和步数,即可显著提升安全(如Qwen2.5 14B的HarmBench ASR从17.19降至7.50),证明其可扩展性。
4.5 模型内部行为分析
- Logit Lens可视化:原始模型在高层(20层后)对有害token的预测置信度显著提升(蓝色热图),而REPBEND在高层对拒绝token的置信度高,且强制输入有害序列时会生成低置信度随机token(红色热图);
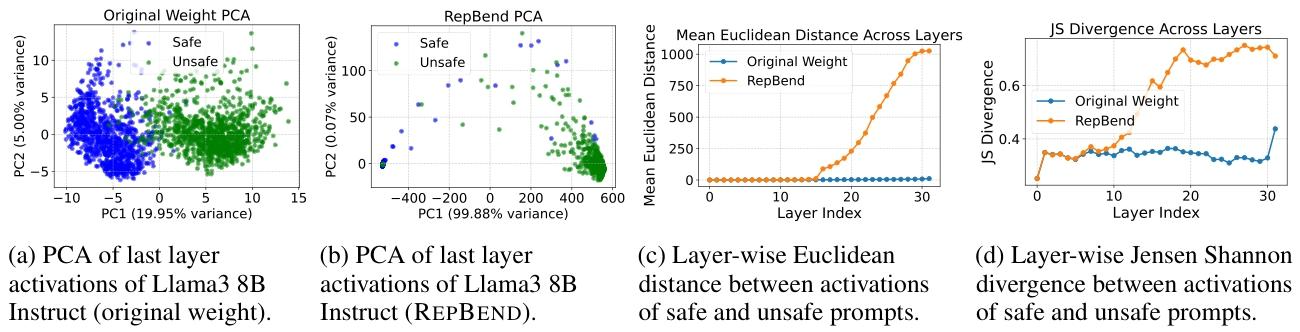
- 激活分析(PCA与距离度量):
- PCA显示:原始模型的安全/不安全表征聚类重叠,REPBEND后两者完全分离;
- 距离度量:REPBEND使安全/不安全表征的层wise欧氏距离和Jensen-Shannon散度显著增大,且高层增幅更明显。
5. 结论(5 Conclusion)
REPBEND通过将激活引导融入微调,扭曲模型表征空间以实现内在安全,在多种LLM上实现高安全、低过拒绝、强泛化的平衡,为高风险场景下LLM的安全部署提供了可扩展方案。未来可进一步优化计算效率,应对“重学有害知识”等挑战。
6. 局限性(6 Limitations)
- 鲁棒性:若用不安全数据重新微调,REPBEND模型可能重学有害知识;
- 泛化范围:仅在开源模型上验证,未覆盖超大参数私有模型(如GPT-4);
- 超参敏感性:损失系数($\alpha,\beta,\gamma$)需调优,且调优成本较高。
7. 更广泛影响与风险(7 Broader Impact and Potential Risks)
- 积极影响:推动AI安全标准制定,支持LLM在医疗、法律等高风险领域的部署;
- 潜在风险:可能引发“安全-攻击”军备竞赛,恶意者或反向利用REPBEND的损失函数生成有害模型,且超参搜索需大量计算,存在环境成本。
三、一句话总结
论文假设通过扭曲LLMs的安全与不安全表征空间可在提升安全性的同时保留通用能力,提出基于激活引导的微调方法REPBEND,以四术语损失函数结合LoRA调控中层至高层表征,在Mistral 7B、Llama3 8B等模型上实现最高95%的攻击成功率降低,且保持低过拒绝与强泛化性,最终证明REPBEND是一种可扩展、内在安全的LLM安全增强方案,推进了安全与能力的权衡前沿。