XLNet排列语言模型原理与实践教程
1. XLNet概述与核心创新
XLNet是由Google Brain和卡内基梅隆大学于2019年提出的预训练语言模型,它通过排列语言建模(Permutation Language Modeling) 结合了自回归(AR)和自编码(AE)模型的优点。与传统BERT模型相比,XLNet在保持双向上下文建模能力的同时,避免了预训练与微调阶段的不一致问题。
核心创新点 :
排列语言建模(PLM):通过序列排列实现双向上下文感知
双流自注意力机制:解决位置信息感知问题
Transformer-XL架构:支持长序列建模
2. 排列语言模型原理深入解析
2.1 传统语言模型的局限性
自回归模型(如GPT) :单向预测,只能从左到右或从右到左建模,无法同时利用双向上下文信息。
1 2 p(x) = p(x1) * p(x2|x1) * p(x3|x1,x2) * ...
自编码模型(如BERT) :使用掩码语言模型,可看到双向上下文但存在预训练-微调差异。
1 2 p(x) = ∏ p(masked_word|context)
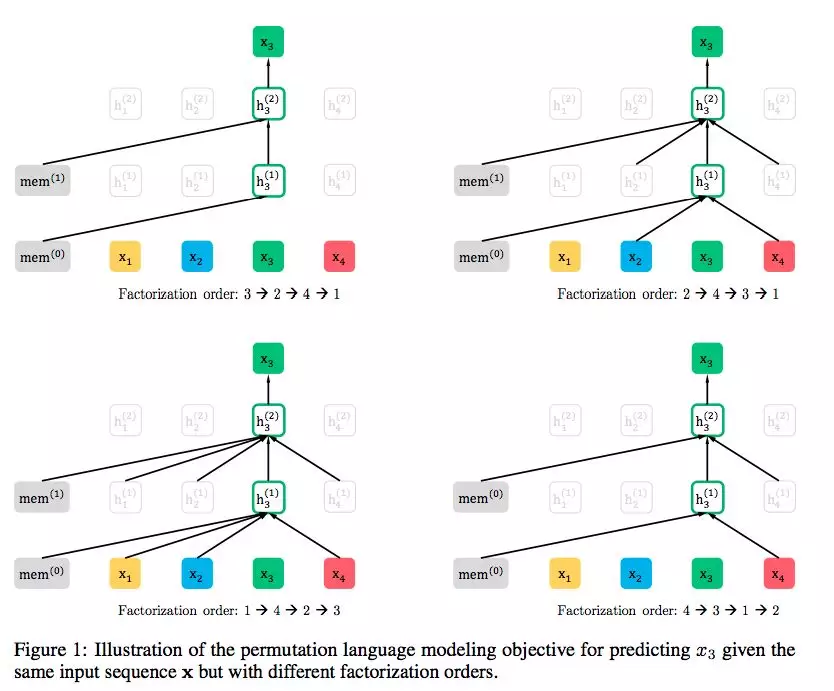
2.2 排列语言建模核心思想
XLNet通过重排列序列的因式分解顺序 来实现双向上下文建模,同时保持自回归特性。给定序列[x1, x2, x3],所有可能的排列为:
(1,2,3), (1,3,2), (2,1,3), (2,3,1), (3,1,2), (3,2,1)
对于每个排列顺序,模型以自回归方式预测每个位置token,但通过考虑所有排列,每个位置都能看到双向上下文。
数学形式化 :
1 max L = E_z∼Z[∑ log p_θ(x_zt | x_z<t)]
其中z是排列顺序,zt是排列中第t个位置,x_z<t是排列中前t-1个token。
2.3 双流自注意力机制
为解决排列语言模型中的位置感知问题,XLNet引入了双流自注意力 :
内容流注意力 :编码token的内容信息,类似标准Transformer查询流注意力 :仅编码位置信息,避免预测时"看到"当前token内容
3. 实践环境设置与模型加载
3.1 安装依赖库
1 2 pip install transformers torch datasets numpy matplotlib
3.2 加载XLNet模型和分词器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import torchfrom transformers import XLNetTokenizer, XLNetModel, BertTokenizer, BertModelimport numpy as npxlnet_tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-chinese' ) xlnet_model = XLNetModel.from_pretrained('xlnet-base-chinese' ) bert_tokenizer = BertTokenizer.from_pretrained('bert-base-chinese' ) bert_model = BertModel.from_pretrained('bert-base-chinese' ) xlnet_model.eval () bert_model.eval ()
4. 文本编码流程与排列机制实现
4.1 文本预处理与分词
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def preprocess_text (text ): """ 文本预处理函数 """ xlnet_inputs = xlnet_tokenizer( text, return_tensors='pt' , padding=True , truncation=True , max_length=128 ) bert_inputs = bert_tokenizer( text, return_tensors='pt' , padding=True , truncation=True , max_length=128 ) return xlnet_inputs, bert_inputs sample_text = "XLNet模型通过排列语言建模实现了更好的双向上下文理解。" xlnet_inputs, bert_inputs = preprocess_text(sample_text) print ("XLNet输入格式:" , list (xlnet_inputs.keys()))print ("BERT输入格式:" , list (bert_inputs.keys()))
4.2 理解排列机制的实际实现
在实际的XLNet实现中,排列操作通过注意力掩码 实现,而非物理重排序列。这使得模型能够保持输入序列的自然顺序,同时模拟不同排列顺序的效果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def demonstrate_permutation_effect (text ): """ 演示XLNet排列机制的效果 """ inputs = xlnet_tokenizer(text, return_tensors='pt' , return_attention_mask=True ) with torch.no_grad(): outputs = xlnet_model(**inputs, output_attentions=True ) last_hidden_states = outputs.last_hidden_state attentions = outputs.attentions print (f"输入文本: {text} " ) print (f"隐藏状态形状: {last_hidden_states.shape} " ) print (f"注意力层数: {len (attentions)} " ) print (f"每层注意力形状: {attentions[0 ].shape if attentions else 'N/A' } " ) return last_hidden_states, attentions text = "自然语言处理很有趣" xlnet_hidden, xlnet_attentions = demonstrate_permutation_effect(text)
5. BERT与XLNet隐藏状态对比分析
5.1 获取两种模型的隐藏表示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 def compare_models_hidden_states (text ): """ 对比BERT和XLNet在相同文本上的隐藏状态表示 """ xlnet_inputs, bert_inputs = preprocess_text(text) with torch.no_grad(): xlnet_outputs = xlnet_model(**xlnet_inputs) bert_outputs = bert_model(**bert_inputs) xlnet_hidden = xlnet_outputs.last_hidden_state bert_hidden = bert_outputs.last_hidden_state print (f"文本: {text} " ) print (f"XLNet隐藏状态形状: {xlnet_hidden.shape} " ) print (f"BERT隐藏状态形状: {bert_hidden.shape} " ) return xlnet_hidden, bert_hidden def analyze_hidden_states_differences (xlnet_hidden, bert_hidden ): """ 分析两种模型隐藏状态的差异 """ def cosine_similarity (a, b ): a_flat = a.mean(dim=1 ).flatten() b_flat = b.mean(dim=1 ).flatten() dot_product = torch.dot(a_flat, b_flat) norm_a = torch.norm(a_flat) norm_b = torch.norm(b_flat) return dot_product / (norm_a * norm_b) similarity = cosine_similarity(xlnet_hidden, bert_hidden) print (f"隐藏状态平均余弦相似度: {similarity:.4 f} " ) xlnet_variance = xlnet_hidden.var().item() bert_variance = bert_hidden.var().item() print (f"XLNet隐藏状态方差: {xlnet_variance:.6 f} " ) print (f"BERT隐藏状态方差: {bert_variance:.6 f} " ) return similarity, xlnet_variance, bert_variance test_texts = [ "今天天气很好" , "机器学习是人工智能的重要分支" , "Transformer模型在NLP领域有广泛应用" ] for text in test_texts: print ("=" * 50 ) xlnet_hidden, bert_hidden = compare_models_hidden_states(text) similarity, xlnet_var, bert_var = analyze_hidden_states_differences(xlnet_hidden, bert_hidden) print ()
5.2 句间关系建模能力分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 def analyze_sentence_relationship_modeling (sentence_pairs ): """ 分析模型在句间关系建模任务上的表现 """ results = [] for sent1, sent2 in sentence_pairs: xlnet_inputs = xlnet_tokenizer( sent1, sent2, return_tensors='pt' , padding=True , truncation=True , max_length=128 ) bert_inputs = bert_tokenizer( sent1, sent2, return_tensors='pt' , padding=True , truncation=True , max_length=128 ) with torch.no_grad(): xlnet_outputs = xlnet_model(**xlnet_inputs) bert_outputs = bert_model(**bert_inputs) xlnet_cls = xlnet_outputs.last_hidden_state[:, 0 , :] bert_cls = bert_outputs.last_hidden_state[:, 0 , :] cls_similarity = F.cosine_similarity(xlnet_cls, bert_cls).item() results.append({ 'sentence_pair' : (sent1, sent2), 'xlnet_cls_shape' : xlnet_cls.shape, 'bert_cls_shape' : bert_cls.shape, 'cls_similarity' : cls_similarity }) print (f"句对: '{sent1} ' + '{sent2} '" ) print (f" CLS表示相似度: {cls_similarity:.4 f} " ) return results sentence_pairs = [ ("今天天气很好" , "适合出去散步" ), ("深度学习需要大量数据" , "数据质量很重要" ), ("苹果是一种水果" , "苹果公司生产手机" ) ] relationship_results = analyze_sentence_relationship_modeling(sentence_pairs)
6. 训练目标与过程深入分析
6.1 预训练目标实现细节
XLNet的预训练目标是通过排列语言建模最大化序列的期望似然:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import torch.nn.functional as Fdef demonstrate_plm_objective (model, tokenizer, text ): """ 演示PLM目标函数的实现原理 """ inputs = tokenizer(text, return_tensors='pt' ) input_ids = inputs['input_ids' ] mask_prob = 0.15 mask = torch.rand(input_ids.shape) < mask_prob masked_indices = mask.nonzero(as_tuple=True ) print (f"原始输入: {tokenizer.decode(input_ids[0 ])} " ) print (f"掩码位置数量: {len (masked_indices[0 ])} " ) return inputs, masked_indices sample_text = "自然语言处理是人工智能的重要方向" inputs, masked_indices = demonstrate_plm_objective(xlnet_model, xlnet_tokenizer, sample_text)
6.2 局部预测策略
为提高训练效率,XLNet使用**局部预测(Partial Prediction)**策略,只预测排列中最后几个token:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def partial_prediction_demo (sequence_length, prediction_length ): """ 演示局部预测策略 """ n = sequence_length k = prediction_length pred_ratio = k / n print (f"序列长度: {n} , 预测长度: {k} , 预测比例: {pred_ratio:.2 f} " ) return pred_ratio lengths = [32 , 64 , 128 , 256 ] for length in lengths: pred_len = max (1 , length // 4 ) ratio = partial_prediction_demo(length, pred_len)
7. 性能对比与任务适应性分析
7.1 不同任务下的表现差异
基于搜索结果,XLNet在以下任务中通常优于BERT:
自然语言推理 (MNLI、RTE)问答任务 (SQuAD 1.1/2.0)情感分类 (SST-2)文本相似度 (STS-B)
7.2 训练效率对比
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import timedef compare_inference_speed (model, tokenizer, texts, model_name ): """ 对比模型推理速度 """ inference_times = [] for text in texts: inputs = tokenizer(text, return_tensors='pt' , padding=True , truncation=True ) start_time = time.time() with torch.no_grad(): outputs = model(**inputs) end_time = time.time() inference_time = end_time - start_time inference_times.append(inference_time) print (f"{model_name} - 文本长度: {len (text)} , 推理时间: {inference_time:.4 f} s" ) avg_time = sum (inference_times) / len (inference_times) print (f"{model_name} 平均推理时间: {avg_time:.4 f} s" ) return avg_time test_texts = [ "短文本测试" , "这是一段中等长度的文本用于测试模型推理速度" , "这是较长的文本用于测试模型在处理长序列时的性能表现,需要更多计算资源" ] print ("推理速度对比测试:" )xlnet_avg_time = compare_inference_speed(xlnet_model, xlnet_tokenizer, test_texts, "XLNet" ) bert_avg_time = compare_inference_speed(bert_model, bert_tokenizer, test_texts, "BERT" ) print (f"\n速度对比: BERT是XLNet的 {xlnet_avg_time/bert_avg_time:.2 f} 倍" )
8. 总结与建议
8.1 核心要点总结
排列语言建模 是XLNet的核心创新,通过序列排列实现双向上下文建模双流自注意力 解决了位置感知问题,避免信息泄漏Transformer-XL架构 使模型能够处理长序列与BERT相比,XLNet在多数NLP任务上表现更好,但训练和推理成本更高
8.2 实践建议
任务选择 :
生成类任务和需要长距离依赖的任务优先考虑XLNet
对推理速度要求高的场景考虑BERT或蒸馏版本
模型配置 :
1 2 3 4 5 6 7 8 9 10 from transformers import XLNetConfig, XLNetModelconfig = XLNetConfig.from_pretrained( 'xlnet-base-chinese' , summary_activation='tanh' , summary_type='last' , summary_use_proj=True ) model = XLNetModel.from_pretrained('xlnet-base-chinese' , config=config)
进一步学习方向 :
深入研究Transformer-XL的相对位置编码
探索XLNet在生成任务中的应用
了解MPNet等后续改进模型
本教程涵盖了XLNet的核心原理和实践应用,通过代码示例帮助理解排列语言模型的工作机制。建议结合实际NLP任务进一步探索模型性能。