Unveiling the Truth and Facilitating Change: Towards Agent-based Large-scale Social Movement Simulation
Unveiling the Truth and Facilitating Change: Towards Agent-based Large-scale Social Movement Simulation 2024.6
ACL
一、论文概览
1. 核心问题
现有社交媒体社会运动模拟方法存在三大关键挑战:
- 准确性:如何精准模拟社交媒体用户的社区行为与态度动态;
- 效率:LLM(大语言模型)虽能模拟复杂行为,但大规模部署(如数千个LLM)成本过高,难以覆盖海量用户;
- 评估:缺乏统一的基准与多维度评估策略,无法全面验证模拟效果。
2. 主要贡献
- 提出混合模拟框架HiSim:基于社交媒体用户参与的帕累托分布,将用户分为“核心用户”(活跃且有影响力,如意见领袖,用LLM建模)与“普通用户”(海量沉默用户,用演绎式Agent-based Models(ABM)建模),平衡准确性与效率;
- 构建类Twitter社会运动模拟器:包含时间线消息流、离线新闻推送机制,可模拟用户交互与集体态度演化;
- 建立首个社会运动模拟基准SoMoSiMu-Bench:涵盖3个真实社会运动数据集(#Metoo、#RoeOverturned、#BlackLivesMatter),并设计微观(个体行为对齐)与宏观(系统舆论动态)双层评估策略。
3. 研究方法
- 混合建模:核心用户采用“LLM+多模块架构”(Profile模块、Memory模块、Action模块),模拟复杂行为;普通用户采用ABM,通过态度更新函数$f_{update}$、选择函数$f_{selection}$、消息函数$f_{message}$模拟态度变化;
- 环境构建:还原Twitter-like生态(个人/公共时间线、离线新闻触发);
- 评估体系:基于SoMoSiMu-Bench,微观评估立场/内容/行为对齐,宏观评估态度分布与时间序列相似度。
二、各章节详解
1. 引言(Introduction)
- 背景:社交媒体是社会运动的核心载体(如阿拉伯之春、#Metoo),但大规模参与可能升级为暴力,需提前预测影响;
- 现有研究局限:传统分析多为“回顾性内容挖掘”(如Giorgi et al., 2022),缺乏模拟预测能力;ABM虽用于社会模拟,但难以捕捉复杂用户行为;LLM在推荐、协作等领域有应用,但大规模社会运动模拟研究较少;
- 提出HiSim框架与三大贡献,概述论文结构。
2. 舆论动力学模拟形式化(Formalization of Public Opinion Dynamics Simulation)
2.1 预备知识
- ABM在舆论动力学中的核心组件:
- 态度更新函数:定义个体态度变化,公式为$\Delta a_{i,t} = a_{i,t+1} - a_{i,t} = f_{update}(a_{i,t}, M_{i,t})$(公式1),其中$a_{i,t}$为用户$i$在$t$时刻的态度($a_{i,t} \in [-1,1]$,符号表方向,绝对值表强度),$M_{i,t}$为用户$i$接收的消息集合;
- 选择函数:确定影响用户$i$的其他用户集合$J_{i,t}$(如基于相似度或平台推荐);
- 消息函数:定义用户$j$传递的消息,公式为$m_{j,t} = f_{message}(a_{j,t})$(公式2),多数ABM假设$m_{j,t}=a_{j,t}$(无偏差传递)。
- LLM赋能智能体:统一架构包含Profile(角色属性)、Memory(经验存储)、Planning(任务拆解)、Action(行为执行)模块,可模拟复杂文本生成行为。
2.2 任务定义
- 目标:模拟用户群体对社会运动的态度演化,对比模拟结果与真实场景;
- 核心变量:用户集合$U$,每个用户$i$的态度$a_{i,t} \in [-1,1]$,基于真实Twitter关注关系构建社交网络,实现“单轮行为复制”与“多轮舆论预测”。
3. 社交媒体模拟混合框架(Hybrid Framework for Social Media Simulation)
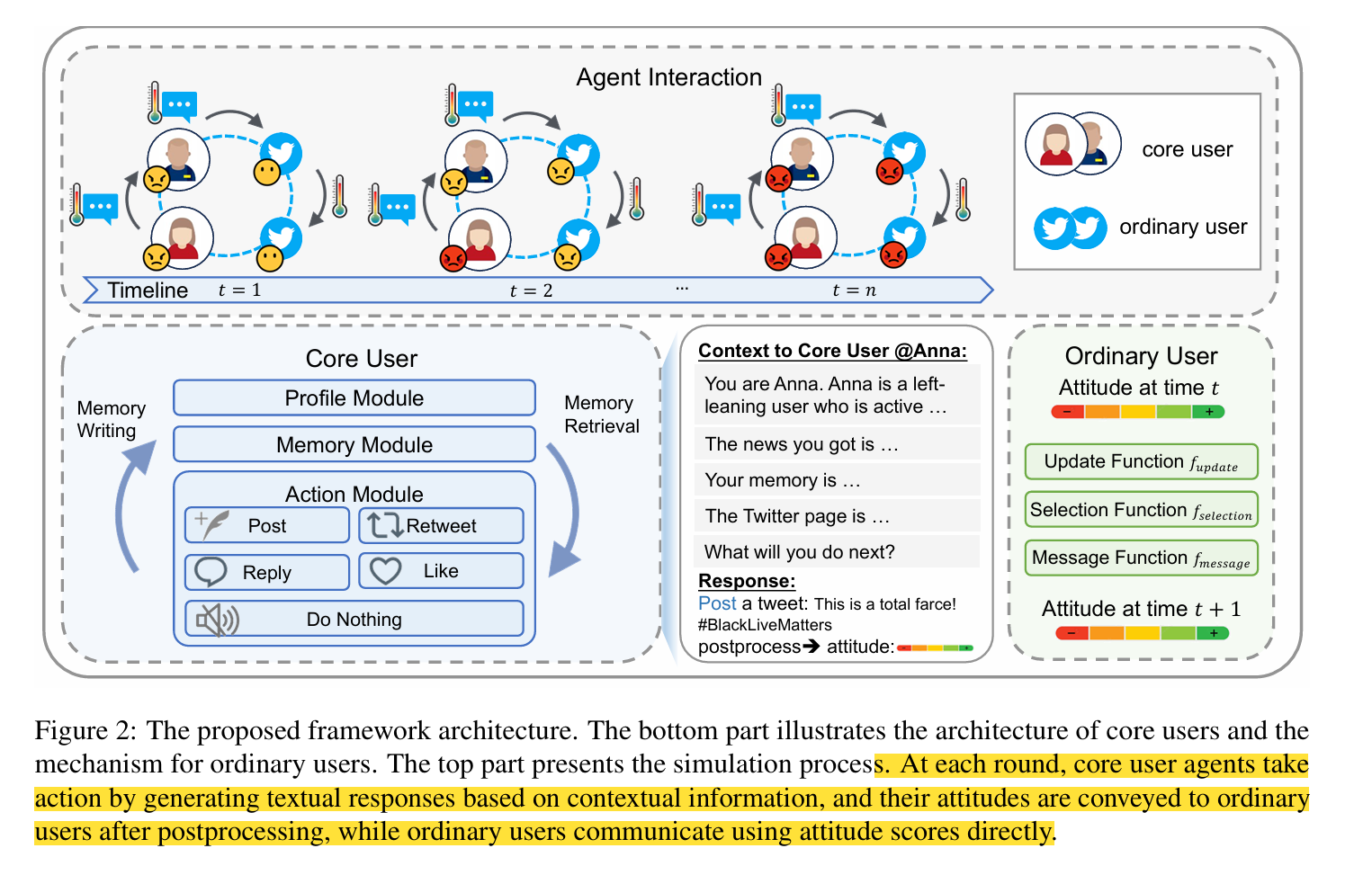
基于帕累托分布(少数用户产生多数内容)分两类用户建模:
3.1 核心用户模拟
- Profile模块:提取真实用户信息,包括:
- 人口统计(性别、政治倾向、账号类型,如活动家/记者);
- 社会特质(活跃度、影响力,分3个层级);
- 传播角色(基于Edelman的TOI框架:Idea Starter/Amplifier/Curator/Commentator/Viewer)。
- Memory模块:
- 内容:个人经验(事件前历史推文)、事件记忆(事件后观察);
- 操作:记忆写入(文本+向量存储)、检索(基于时效性/相关性/重要性/即时性)、反思(定期生成高层洞察)。
- Action模块:支持5种行为:Post(发原创)、Retweet(转发,含直接/附加评论)、Reply(回复)、Like(点赞)、Do Nothing(沉默)。
3.2 普通用户模拟
- 初始态度:基于真实推文标注(用GPT-3.5和TextBlob标注立场与强度);
- 态度变化:采用2.1.1的ABM组件(更新/选择/消息函数)。
3.3 智能体交互
- 同类型:核心用户用自然语言交互,普通用户用ABM消息函数交互;
- 异类型:核心用户生成的文本通过LLM标注立场、情感分析算强度,转化为态度分数输入普通用户ABM。
3.4 模拟环境与过程
- 环境:类Twitter时间线(个人关注者推文+公共推文)、离线新闻推送(如George Floyd事件);
- 过程:单轮(输入真实上下文,验证行为复制)、多轮(输入模拟上下文,预测舆论演化)。
4. SoMoSiMu-Bench:社会运动模拟基准(A Benchmark for Social Movement Simulation)
4.1 数据集
- 覆盖3个社会运动,每个运动2个阶段,统计如下(表1):
数据集 阶段 用户数 推文数 时间范围 Metoo E1(#Metoo启动) 1000 18638 2017-10-15至22 E2(#Timesup活动) 1000 13291 2018-01-06至13 RoeOverturned E1(最高法院草案泄露) 1000 61687 2022-05-02至09 E2(推翻Roe v. Wade) 1000 59829 2022-06-24至07-01 BlackLivesMatter P1(Floyd遇害后) 1000 10710 2020-05-25至06-01 P2(后续阶段) 1000 21480 2020-06-02至09 - 用户选择:300核心用户(前100高影响力+200高活跃)、700普通用户(随机抽样)。
4.2 微观对齐评估
- 立场对齐:分类支持/中立/反对,报告Acc、F1、态度分数MAE;
- 内容对齐:分类Call for Action/Sharing of Opinion等5类,报告Acc、F1、文本余弦相似度;
- 行为对齐:评估Post/Retweet选择,报告Acc、F1。
4.3 宏观系统评估
- 静态态度分布:Bias(均值偏离中立的程度)、Diversity(态度标准差),报告$\Delta Bias$(模拟-真实)、$\Delta Div$;
- 时间序列:用DTW(动态时间规整)衡量相似度、Pearson相关系数衡量趋势一致性;
- 参数校准:在纯ABM上通过参数扫描(如$\alpha$、$\varepsilon$)找最优参数,应用于混合模型。
5. 实验(Experiments)
5.1 实验设置
- 基线:5种纯ABM(BC、HK、RA、SJ、Lorenz);
- LLM:GPT-3.5-Turbo-0613(max tokens=256,temperature=0,确保确定性);
- 工具:核心用户用AgentVerse,普通用户用mesa库;
- 模拟步数:每个事件14步(基于真实用户平均发帖间隔)。
5.2 微观对齐结果(表2)
- 立场:Acc高达0.899-0.968,但F1低(0.336-0.374),因LLM倾向生成明确立场,缺乏真实用户的复杂行为(如分享链接);
- 内容:余弦相似度近80%,擅长复制“Call for Action”和“Sharing of Opinion”,但难生成“Testimony”(缺乏离线经验);
- 行为:Acc超72%,因Profile模块的社会特质与传播角色有效引导行为选择(消融实验验证,表7)。
5.3 宏观系统结果(表3)
- 混合模型全面优于纯ABM:$\Delta Bias$、$\Delta Div$更小,DTW更低(相似度更高),Pearson相关更高(趋势更一致);
- 最优组合:基于RA和Lorenz的混合模型(因二者擅长模拟极端主义场景,Chuang and Rogers, 2023)。
5.4 可扩展性分析(图3)
- 性能:普通用户数量增加时,除$\Delta Bias$外,其他指标仅轻微下降,支持抽样模拟;
- 效率:运行时主要依赖LLM API调用,普通用户规模扩大(至1万)几乎无额外开销,可扩展至百万级(需硬件优化)。
5.5 进一步分析
- 回声室复制:内容生产与消费的相似度随轮次上升(图4),验证框架能还原回声室现象;
- 干预策略:S3(建立公共讨论空间)在减少回声室的同时,毒性最低(表4),优于S1(投喂对立观点,增加毒性)和S2(投喂中立观点)。
6. 相关工作(Related Work)
- 社交媒体用户建模:从文本特征工程→图融合,LLM前局限于离散属性预测;
- LLM赋能智能体:应用于推荐、协作,但大规模社会模拟研究少;
- 社会模拟:ABM分演绎(如BC模型)与归纳(依赖人类实验,成本高),LLM有望替代人类被试。
7. 结论与局限(Conclusion & Limitations)
- 结论:HiSim框架通过LLM-ABM混合建模,在SoMoSiMu-Bench上验证了有效性与灵活性;
- 局限:数据规模未达百万级(标注成本)、LLM生成内容偏向礼貌(与真实社交媒体用户有偏差);
- 伦理:数据隐私(分享tweet id而非原始数据)、模拟向善(避免滥用标签,需告知工具局限)。
三、一句话总结
论文假设社交媒体用户参与符合帕累托分布,提出HiSim混合框架(核心用户用LLM+Profile/Memory/Action模块模拟复杂行为,普通用户用ABM高效模拟),构建类Twitter环境与SoMoSiMu-Bench基准,实验表明该框架在微观行为对齐(立场Acc超89%、行为Acc超72%)、宏观舆论预测(优于纯ABM)、可扩展性(支持万级用户)上表现优异,能还原回声室现象且S3干预策略可有效缓解回声室,为大规模社会运动模拟提供有效方案。