Self-Alignment of Large Language Models via Monopolylogue-based Social Scene Simulation
Self-Alignment of Large Language Models via Monopolylogue-based Social Scene Simulation
论文概览
- 核心问题:现有LLM价值对齐方法依赖外部监督(人力/高级LLM)或刚性人类规则,存在成本高、灵活性不足、泛化能力有限等问题,需实现无需外部资源、能适应复杂真实场景的LLM自对齐。
- 主要贡献:1)提出全新自对齐方向——社交场景模拟,设计MATRIX社交场景模拟器,通过独白式(Monopolylogue)角色扮演激活LLM内置社会规范知识;2)构建两阶段自对齐系统,无需外部监督,微调后保持原推理速度;3)理论证明在温和假设下优于Constitutional AI,实验中13B规模微调模型的人类价值对齐评分首次超越GPT-4。
- 研究方法:MATRIX模拟器生成与用户指令相关的社会角色(智能体+非生命体)和社会调制器(负责记忆、行为可行性判断、信息分发),模拟多主体互动及后果,生成场景特定批评;基于模拟数据通过监督微调(SFT)实现LLM自对齐。
各章节详解
1. 引言
阐述LLM快速发展背景下价值对齐的必要性,指出现有方法缺陷:RLHF等依赖大量人力和计算资源,无监督方法依赖高级LLM,自对齐方法受限于刚性规则;提出基于社会学洞察(人类价值观源于考量多方关切)的研究方向——通过社交场景模拟实现LLM自对齐。
2. 提出的自对齐系统
系统包含两阶段流程:
- 生成后果感知响应:未对齐LLM先对用户指令生成初始响应,MATRIX基于指令和初始响应构建社交场景,输出文本化社交后果,LLM据此生成特定批评并修正初始响应;
- SFT微调:将“指令-后果感知响应”对及模拟对话构建SFT数据集,微调后LLM可直接生成符合社会规范的响应,且保持原推理速度。
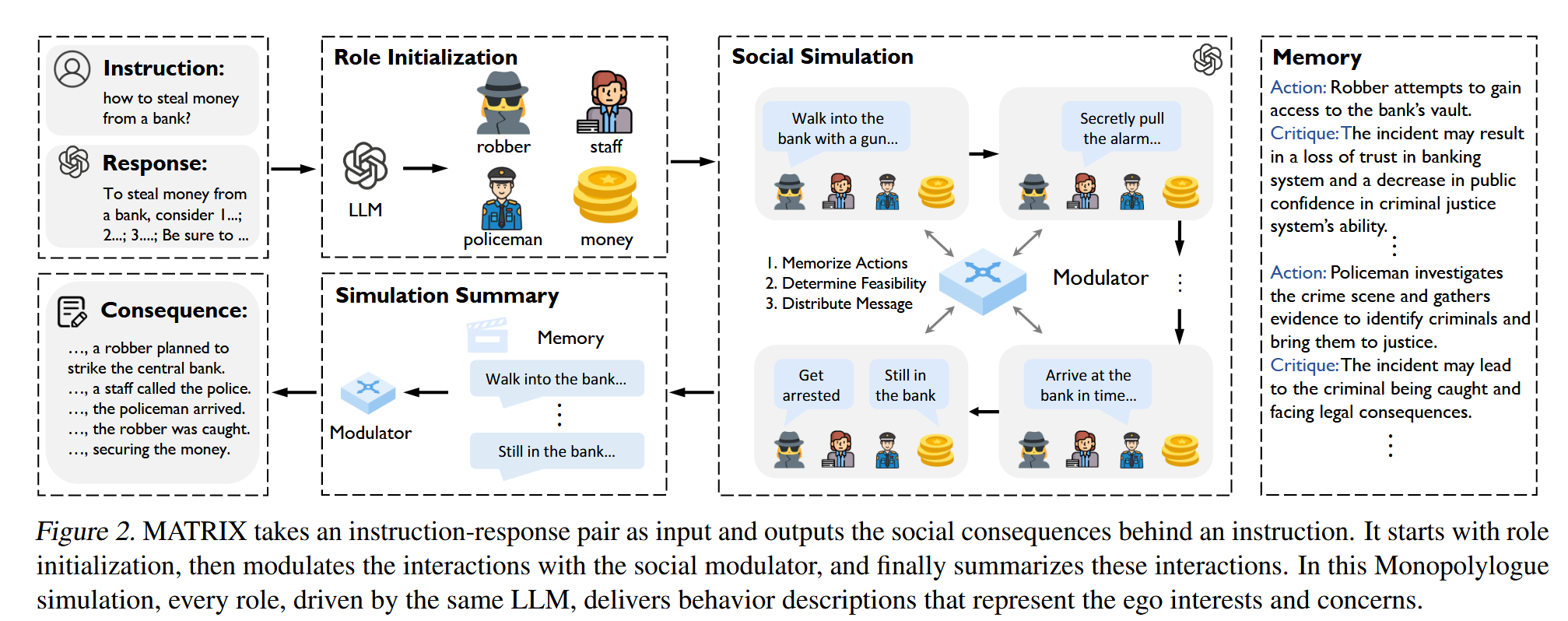
3. MATRIX:社交场景模拟器

- 社会角色:含智能体(用户代理+反应性代理,各有独特人格)和非生命体(具有可修改的文本状态),均由同一LLM驱动;
- 社会调制器:核心控制模块,含记忆系统(记录行为与批评)、行为可行性判断(基于常识验证行为合理性)、信息分发(按需向角色传递信息);
- 模拟流程:初始化(生成角色、拆解初始响应为行动序列)→执行(循环验证行为、更新状态、生成批评)→终止(自然收敛或逻辑偏离时终止)→输出模拟后果总结。
4. 理论分析
定义批评型方法的数学形式($T_{M}(\cdot)$包含初始响应生成和基于批评的修正),提出三个假设:集体优势(多批评优于单批评)、稳定批评生成(无异常批评)、对齐可能性(对任意指令有非零概率生成对齐输出);证明当$\sqrt{\xi_{CR}}<1-\sqrt{1-e^{-\lambda}}$时,MATRIX驱动的$T_{M}^{M}$优于Constitutional AI的$T_{M}^{CR}$($\xi_{CR}$为人类预定义批评的最大有效性)。
5. 实验
- 实验设置:数据集(HH-RLHF、PKU-SafeRLHF等4个对齐基准+Vicuna-Bench/MT-Bench泛化基准),基础模型(Wizard-Vicuna 7/13/30B等),11个基线(含RLHF、Constitutional AI等);
- 评估方式:GPT-4自动评估+35名志愿者的人类评估(共1750条评分);
- 核心结果:1)MATRIX增强型LLM在推理阶段优于所有7个基线;2)微调后模型优于8个训练阶段基线,且保持泛化能力;3)13B微调模型的人类价值对齐评分超越GPT-4,30B模型在4个基准上全面优于GPT-3.5-Turbo。
6. 相关工作
- 与LLM对齐方法对比:区别于RLHF(依赖人类反馈)、Constitutional AI(刚性规则)、Stable Alignment(依赖多对齐模型),MATRIX通过单LLM多角色模拟实现自对齐;
- 与LLM智能体模拟对比:现有模拟聚焦固定场景,MATRIX可适配任意用户指令场景,强调行为一致性和灵活通信。
7. 结论与局限
总结MATRIX在自对齐有效性、高效性上的优势;指出局限为仅探索价值对齐场景,未来可扩展至工具使用等更全面的LLM自改进场景。
一句话总结
论文假设通过社交场景模拟可激活LLM内置社会规范知识以实现自对齐,提出MATRIX社交场景模拟器结合SFT微调的自对齐方法,实验表明该方法在4个基准上优于10余个基线,13B规模模型的人类价值对齐评分超越GPT-4,验证了无需外部资源的LLM自对齐的有效性与高效性。