Zero-shot Persuasive Chatbots with LLM-Generated Strategies and Information Retrieval
Zero-shot Persuasive Chatbots with LLM-Generated Strategies and Information Retrieval
论文概览
本文假设通过从大语言模型(LLMs)生成的响应中提取灵活多样的说服策略,并结合信息检索(IR)替换未证实的声称以解决幻觉问题,可实现零样本场景下兼具高说服力与事实准确性的聊天机器人;提出了包含策略维护模块(SMM)和问题处理模块(QHM)的PersuaBot框架,在捐赠动员、旅游推荐、健康干预三个领域的模拟与真实用户实验中,其事实性超越现有知识导向聊天机器人(最高比GPT-3.5高$26.6%$),说服力在$5$-point scale中比现有方法高$0.6$,验证了该零样本方法的有效性与领域适应性,为社会公益等场景的负责任说服技术提供了新方案。
核心问题
现有说服式聊天机器人存在三大局限:一是依赖特定任务标注训练数据,收集成本高甚至不可行;二是仅采用少量预定义说服策略,灵活性不足;三是LLM-based方法易产生幻觉(虚构信息),既破坏用户信任,又难以在消除幻觉的同时保留说服力,且在零样本场景下适配多领域的能力薄弱。
主要贡献
- 首次实现零样本、高事实性与高说服力的LLM-based聊天机器人,无需任务特定对话数据和预定义策略。
- 在三个差异显著的领域中,PersuaBot的事实性超越SOTA知识导向聊天机器人,说服力优于现有手动设计规则或模块化说服聊天机器人。
- 验证了同一技术框架的跨领域适应性,可直接应用于捐赠动员、旅游推荐、健康干预等不同说服场景,无需额外微调或领域适配。
研究方法
核心框架:PersuaBot
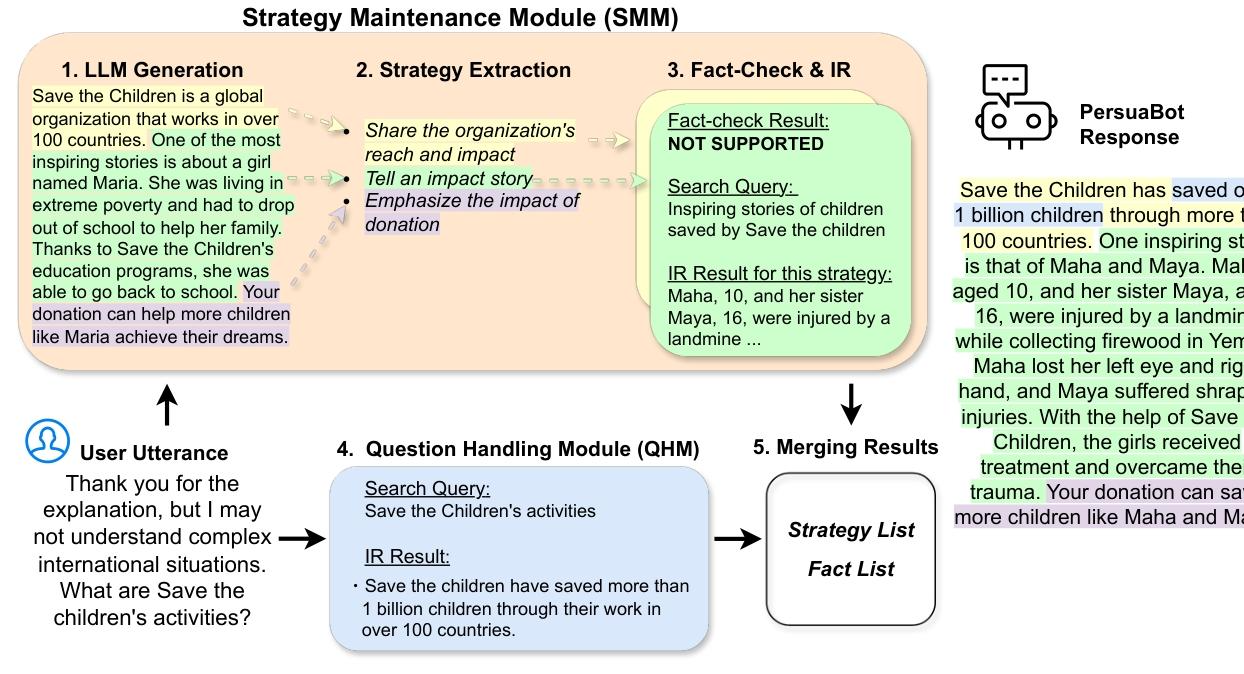
采用双模块并行架构,全程无需领域特定数据,仅依赖通用提示词与任务相关语料库(如官方网站文本):
- 策略维护模块(SMM):先通过LLM生成初始响应,再分解为对应不同说服策略的段落;对每个段落进行事实核查,对未证实的内容,基于策略意图生成检索查询,从语料库中获取真实证据替换,保留原说服策略;无检索结果则移除该策略。
- 问题处理模块(QHM):针对用户 utterance 中的明确查询,通过ColBERT检索语料库获取相关事实,无查询则跳过。
- 结果合并:将两个模块的事实与策略整合,通过提示词引导LLM生成连贯、事实准确且保留说服功能的最终响应,避免信息重复与内在幻觉。
实验设计
- 任务领域:捐赠动员(支持救助儿童组织)、旅游推荐(日本旅行)、健康干预(新冠、流感等呼吸道病毒防护)。
- 基线模型:原始LLM(GPT-3.5/Llama 3)、SOTA知识导向聊天机器人(Semnani et al., 2023)、手动设计说服聊天机器人(Chen et al., 2022)。
- 评估指标:说服力(Persuasive)、相关性(Relevant)、自然度(Natural)、诚实度(Honest)(均为$1$-5分制),事实性(Fact-Checked,百分比)。
- 实验类型:模拟对话实验(设计“软用户”“硬用户”各20种人格,生成400组对话)、真实用户实验(160名受试者,聚焦捐赠动员领域)。
论文各章节详解
1. 摘要与引言
- 摘要:明确说服技术在社会公益、健康干预等领域的重要价值,指出现有方法的局限,提出PersuaBot的核心设计(LLM生成策略+信息检索去幻觉),并概括其在三个领域的实验优势。
- 引言:界定说服式技术的定义与应用场景,阐述现有研究的不足(依赖标注数据、策略静态、幻觉问题);提出PersuaBot的三大核心特性(事实准确、用户自适应、领域自适应);概述方法框架与核心贡献。
2. 相关工作
- 事实性聊天机器人:梳理LLM幻觉问题的解决方案,包括知识图谱、外部语料库检索增强(如LLM-AUGMENTER),指出现有方法在保留说服力方面的欠缺。
- 说服式聊天机器人策略:总结现有研究依赖预定义对话行为、静态策略或特定任务数据集的现状,提及RAP框架、模板化响应等方法,强调动态策略对泛化能力的重要性。
- 研究缺口:现有方法难以兼顾动态策略、零样本适配、事实准确性与说服力,PersuaBot针对性解决该缺口。
3. 方法:PersuaBot
- 策略维护模块(SMM):详细拆解“LLM生成响应→策略提取→事实核查与检索→策略保留/替换”流程,策略提取采用LLM动态生成标签(非预定义),检索查询基于策略意图优化,提升相关性。
- 问题处理模块(QHM):说明用户查询识别与检索逻辑,确保对用户明确问题的响应准确性。
- 结果合并:描述基于提示词的响应生成规则,要求整合策略与事实、避免重复、保持连贯性,示例展示如何替换幻觉内容(如将虚构的“Maria故事”替换为真实的“Maha和Maya案例”)。
4. 实验设置
- 任务细节:明确三个领域的核心目标与语料来源(救助儿童组织、日本国家旅游局、CDC官网),语料直接用于ColBERT检索,无需修改。
- 基线模型:说明各基线的核心机制(如Semnani et al.的检索增强、Chen et al.的预定义策略与议程推送),以及其适用范围限制(如Chen et al.仅适用于捐赠领域)。
- 评估方法:详细说明模拟用户的人格设计逻辑(软用户易被说服,硬用户怀疑/冷漠)、真实用户实验的流程(角色扮演对话+问卷评估);事实性评估采用“3名标注员+语料库复核”机制,区分“事实核查通过”“错误”“信息不足”三类标注结果。
5. 模拟对话实验
- 结果分析:呈现各模型在不同领域、不同用户类型下的评估指标,PersuaBot在说服力、事实性上全面领先,相关性与自然度与原始LLM相当。
- 策略分析:统计发现PersuaBot在三个领域分别生成72、82、51种细分策略(远超现有方法的预定义策略数量),且策略分布贴合领域特性(如旅游推荐侧重“具体目的地推荐”,健康干预侧重“预防强调”)。
- 案例展示:通过与“硬用户”的对话示例,体现PersuaBot的用户自适应能力(如针对自我中心的用户强调捐赠的个人税务收益)。
6. 真实用户实验
- 结果:聚焦捐赠动员领域,PersuaBot的说服力($3.9\pm0.7$)显著高于基线(Chen et al.为$3.3\pm1.1$),事实性达$94.3%$,远超原始GPT-3.5($76.1%$)。
- 用户反馈:正面评价集中于“提供充分捐赠理由”“对话自然”,负面评价主要为“部分响应重复”;基线模型的不足包括“说服力弱”(Semnani et al.)、“不诚实(伪装人类捐赠)”(Chen et al.)。
7. 结论、局限与伦理考量
- 结论:重申PersuaBot通过“策略提取+事实检索”实现零样本说服的核心价值,验证其在事实性与说服力上的突破。
- 局限:难以生成比LLM固有策略更复杂的说服策略;未核查LLM自身的观点类内容,可能存在伦理风险;对“硬用户”的重复拒绝响应优化不足。
- 伦理考量:强调说服技术的双刃剑属性,提出通过内容过滤(如Azure OpenAI过滤器)避免有害内容;确保聊天机器人“诚实”,不伪装人类;实验受试者补偿符合行业标准(约$12$/小时),经IRB批准。