AI-Press: A Multi-Agent News Generating and Feedback Simulation System Powered by Large Language Models
AI-Press: A Multi-Agent News Generating and Feedback Simulation System Powered by Large Language Models
论文概览
本文假设大型语言模型(LLMs)在新闻生成中存在专业性不足、伦理判断欠缺及公众反馈难预测的问题,提出一种融合多智能体协作与检索增强生成(RAG)的自动化新闻起草打磨系统AI-Press,并设计基于人口统计分布的公众反馈模拟机制;通过针对新闻生成质量和反馈模拟效果的定量与定性实验,验证了AI-Press能显著提升新闻生成质量,且模拟反馈与真实公众反馈趋势高度一致,最终证明该系统可有效克服LLMs在新闻行业应用中的核心挑战。
核心问题
- LLM生成新闻缺乏专业性,存在“幻觉”现象,不符合新闻规范与价值要求,难以满足新闻行业对准确性和可信度的高需求。
- LLM在复杂新闻场景中伦理判断能力有限,单纯依赖其进行伦理决策可能导致结果不准确或不当,需人类编辑的关键监督。
- 新闻发布后的公众反馈具有复杂性、动态性和受众异质性,记者难以准确预测不同群体对新闻内容的反应。
主要贡献
- 开发了基于多智能体协作与RAG的自动化新闻起草和打磨系统,支持新闻内容的粗粒度处理(信息收集与起草)和细粒度处理(修改与优化)。
- 实现了贴近真实场景的新闻反馈模拟系统,允许用户自定义受众人口统计分布,为目标新闻推送提供针对性反馈参考。
- 开展了全面的定量与定性评估,涵盖多种新闻体裁和反馈模拟场景,充分验证了系统在新闻生成质量和反馈模拟有效性上的优势。
研究方法
系统框架设计
采用模块化工作流(非端到端),突出“人机协同”(human-in-the-loop),核心包含三大模块: - Press Drafting Module:由Searcher和Writer智能体构成,Searcher从新闻数据库(20万篇权威文章)、事实数据库和互联网检索信息,提取关键要素与事件脉络;Writer依据不同新闻体裁的写作规范,完成标题拟定和新闻初稿起草。 - Press Polishing Module:由Reviewer和Rewriter智能体协作,Reviewer针对新闻体裁提供靶向修改建议,Rewriter执行修改,支持记者自定义打磨轮次,可视化展示协作过程。 - Simulation Module:基于1万条匿名社交媒体用户数据构建带有人口统计标签的用户画像池,可自定义受众性别、年龄、教育水平等特征,生成模拟评论并进行词频统计、情感分析和立场分析。
实验设计
- 新闻生成实验:以300篇涵盖新闻、人物专访、评论三大体裁的权威新闻摘要为测试数据,对比GPT-3.5、GPT-4o、Qwen-2.5等5种LLM在“纯模型”和“模型+AI-Press”两种模式下的生成效果;采用GPT-4o作为评分工具,针对不同体裁设计专属评估指标(如新闻的全面性、深度,人物专访的丰富度、独特性等)。
- 反馈模拟实验:包含模拟方差实验(验证不同人口统计分布对同一新闻的反馈差异)和模拟一致性实验(验证相同分布下模拟反馈与真实反馈的契合度);选取政治、经济、冲突三大领域的新闻及真实用户评论,用GPT-4o标注情感倾向(正负中性)和立场(支持/反对/中性),情感评分范围为[−1, 1],通过核密度估计(KDE)评估模拟效果。
- 消融实验:针对Press Polishing Module的打磨轮次N,探究不同轮次对新闻质量的影响。
各章节详解
1 Introduction
- 背景:社交平台的兴起改变了新闻业格局,LLMs因高效低成本被广泛应用于新闻生产,但同时面临专业性、伦理判断和反馈预测三大挑战。
- 行业现状:记者对LLMs的接受度存在差异,部分担忧职业威胁,部分认可其在客观性、时效性上的优势,多家编辑部已出台LLM使用指南。
- 核心方案:提出AI-Press框架,通过多智能体协作与RAG解决新闻生成质量问题,通过人口统计分布驱动的模拟系统解决反馈预测问题。
2 Related Works
- Retrieval-Augmented Generation(RAG):通过融合外部知识源减少LLM的“幻觉”,提升生成内容的准确性,适用于对真实性要求极高的新闻领域。
- Multi-Agent Framework:借鉴新闻工作的团队协作属性,利用多智能体的多元能力分工解决复杂任务,该框架在医疗、法律等领域已取得显著成果。
- Role-Playing Agents(RPAs):基于LLM构建的角色扮演智能体可模拟不同个体或群体特征,广泛应用于娱乐、心理治疗等领域,为新闻反馈模拟提供技术基础。
3 AI Press System
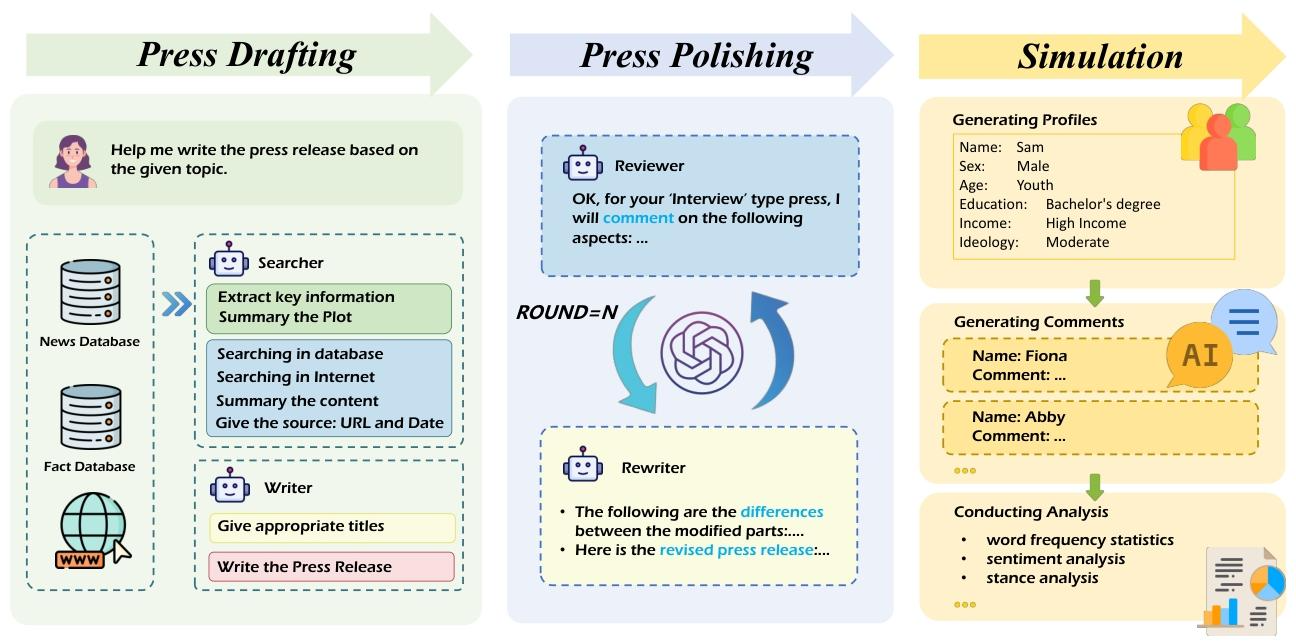
- 框架设计:参考路透社新闻生产流程(收集、处理、发布、反馈),构建三大核心模块,强调记者在整个流程中的主导作用,支持自定义参数(如打磨轮次、受众特征)。
- 模块细节:
- Press Drafting Module:Searcher分两步提取关键信息(事件核心要素、时间线与关键情节),检索来源兼顾专业性与时效性;Writer依据不同体裁指南(新闻强调客观及时、人物专访注重生动深入、评论注重逻辑论证)生成初稿。
- Press Polishing Module:Reviewer针对不同体裁的核心维度提出修改建议(新闻聚焦准确性与时效性,评论聚焦论证充分性与观点清晰度),Rewriter按建议优化初稿,支持多轮迭代。
- Simulation Module:从用户画像池抽取样本生成目标受众,模拟评论需契合其人口统计特征(如年龄、意识形态),输出包含词云、情感分布、立场分布的分析结果。
4 Experimental Setup
- 新闻生成实验:
- 数据:300篇测试新闻涵盖国际、科技、体育等多个领域,避免与系统本地数据库存在数据泄露。
- 基线模型:GPT-3.5、GPT-4o、Claude-3.5、Gemini-1.5 Pro、Qwen-2.5。
- 评估指标:针对新闻、人物专访、评论三大体裁设计差异化指标,均采用0-5分制(新闻:全面性、深度、客观性等;人物专访:丰富度、独特性、启发性等;评论:观点清晰度、证据充分性、相关性等)。
- 反馈模拟实验:
- 数据:选取《纽约时报》政治、经济、冲突领域的三篇高评论量文章,收集真实用户评论并标注人口统计特征。
- 评估方法:模拟方差实验通过对比不同意识形态分布(保守派:温和派:自由派=1 : 0 : 0、1 : 0 : 1、0 : 0 : 1)的反馈差异验证敏感性;模拟一致性实验通过KDE对比模拟评论与真实评论的情感分布契合度。
5 Results
- 新闻生成结果:所有LLM结合AI-Press后生成质量均显著提升,其中GPT-4o+AI-Press在新闻的全面性(3.83分)和深度(3.16分)上表现最优,Qwen-2.5+AI-Press在人物专访所有指标(丰富度3.68分、启发性4.19分等)和评论的相关性(4.92分)上领先;但LLM在评论的全面性和证据充分性上仍未超越专业记者。
- 反馈模拟结果:模拟方差实验显示,随自由派比例增加,负面情感和支持立场的评论显著增多;模拟一致性实验中,模拟评论与真实评论的情感KDE曲线高度相似,证明模拟反馈的真实性。
- 消融实验:打磨轮次N = 2时新闻质量达到最优,继续增加轮次质量无明显提升。
6 Conclusion
- 总结:AI-Press通过多智能体协作与RAG解决了LLM新闻生成的专业性和伦理问题,基于人口统计的反馈模拟系统实现了公众反应的可预测性,实验充分验证了系统有效性。
- 局限:系统对更多新闻体裁的适应性不足,评估未纳入全面的人类评价,未来需进一步研究体裁特征,优化评估指标并加入人类评估环节。