The Truth Becomes Clearer Through Debate! Multi-Agent Systems with Large Language Models Unmask Fake News
The Truth Becomes Clearer Through Debate! Multi-Agent Systems with Large Language Models Unmask Fake News
论文概览
本文假设“结构化多智能体辩论能充分释放大语言模型(LLMs)的推理能力,提升假新闻检测的可解释性与有效性”,提出名为TruEDebate(TED)的多智能体框架,通过DebateFlow Agents模拟正式辩论、InsightFlow Agents整合辩论结果并判断真实性,在ARG-EN和ARG-CN数据集上的实验表明该框架在准确率、macF1等指标上显著优于传统分类模型、单独LLM及LLM+SLM混合方法,最终证实结构化辩论机制能有效增强假新闻检测的准确性与透明度,为负责任信息系统提供支撑。
核心问题
现有假新闻检测方法存在两大关键缺陷:一是传统机器学习模型(如BERT系列)可解释性差、泛化能力有限,难以适配多样化场景;二是直接基于提示词调用LLM的方法未充分利用其推理潜能,易得出简化且仓促的结论,无法从多视角全面评估新闻真实性,导致检测效果与可解释性难以兼顾。
主要贡献
- 提出TED框架,一种基于LLM的可解释假新闻检测方案,通过结构化辩论实现检测功能的同时,提供清晰的推理依据。
- 受林肯-道格拉斯辩论理论启发,设计Synthesis Agent(总结辩论核心观点)与Analysis Agent(整合角色嵌入与辩论交互特征),构建完整的辩论-分析闭环。
- 在ARG-EN和ARG-CN数据集上完成全面验证,TED性能优于各类基线方法,且适配闭源(GPT-4o-mini、Deepseek)与开源(Qwen-2.5、Llama 3.1)LLM骨干模型,展现出强适应性与泛化能力。
研究方法
核心框架设计
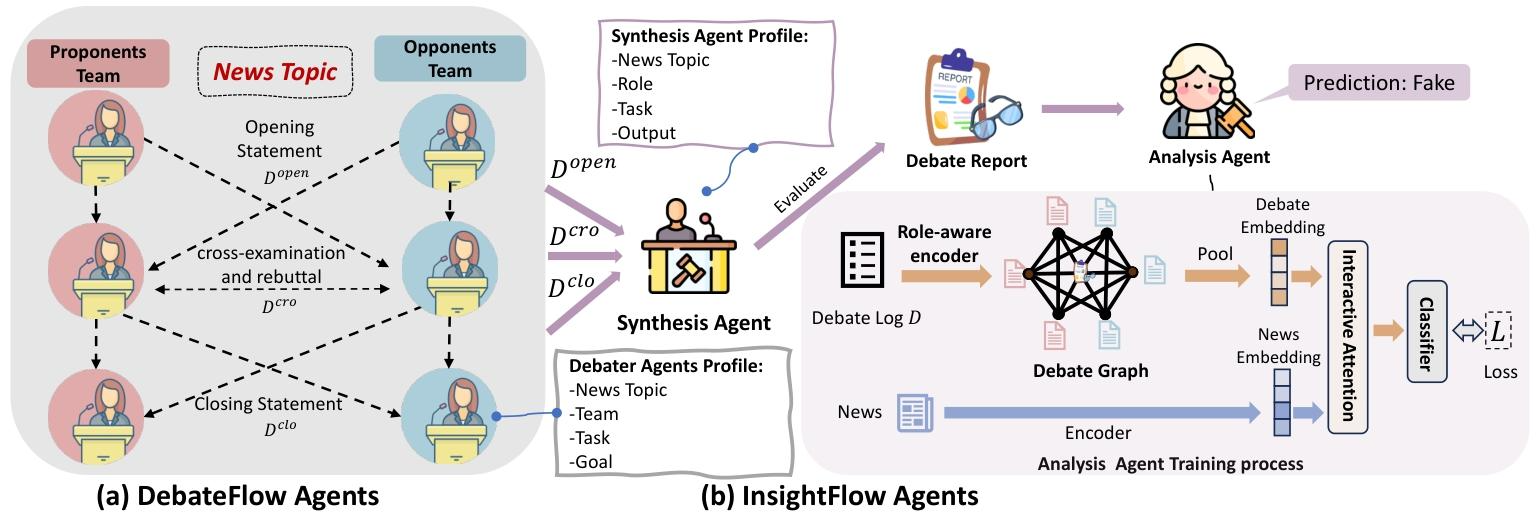
TED框架包含两大核心组件,形成“辩论生成-结果分析”的完整流程: - DebateFlow Agents:将智能体分为支持新闻真实性的“正方”与质疑的“反方”,遵循开场陈述、交叉质询、反驳、总结陈述四个阶段展开辩论,所有交互记录于辩论日志D。 - InsightFlow Agents:Synthesis Agent对辩论日志D进行汇总,生成涵盖核心论据与反论据的综合报告S;Analysis Agent通过角色感知编码器、辩论图(GAT处理)及新闻-辩论交互注意力机制,整合报告S与原始新闻F,输出最终真实性判断ŷ。
关键技术细节
- 辩论阶段建模:通过Prompt函数定义各阶段智能体行为,如开场陈述di(1) = farg(F, Stancei)、交叉质询与反驳dj(2) = freb(D(1), Stancej)、总结陈述dk(3) = fclo(D(1) ∪ D(2), Stancek)。
- Analysis Agent核心机制:角色感知编码器通过[hienc; riproj]整合文本语义与角色特征;辩论图用GAT捕捉论据交互关系hi(l + 1) = σ(∑j ∈ 𝒩(i)αij(l)W(l)hj(l));交互注意力机制通过c = MHA(eFproj, gproj, gproj)融合新闻与辩论信息。
- 训练目标:最小化交叉熵损失ℒ = −∑kyklogŷk,其中ŷ = softmax(Wfch + bfc)为预测概率分布。
论文各章节详解
1. 引言(Introduction)
- 背景:假新闻通过社交网络快速传播,对选举、公共卫生、社会稳定造成严重影响,亟需高效且可解释的检测方法。
- 现有方法局限:传统机器学习模型(如BERT)可解释性差、泛化弱;直接调用LLM的方法未充分利用其推理能力,结论片面。
- 研究动机:基于“真理越辩越明”的理念,引入结构化辩论机制,模拟人类多视角评估信息的认知过程。
- 核心方案:提出TED框架,通过多智能体辩论实现深度推理与可解释检测,概述框架核心组件与实验优势。
2. 相关工作(Related Work)
2.1 假新闻检测
- 早期研究:依赖新闻文本的传统模型(如卷积神经网络、BERT),或融合多模态数据、情感特征的改进方法。
- 近期研究:LLM+SLM混合模型(如ARG、SuperICL),但未充分释放LLM推理潜能,且缺乏结构化交互机制。
2.2 LLM多智能体讨论
- 现有研究:ChatEval(多智能体验证模型输出)、ReConcile(加权投票达成共识)等,但未真正模拟辩论流程,难以多视角分析问题。
2.3 LLM多智能体系统
- 应用场景:模拟社交媒体内容、虚拟开发团队等,但仅关注智能体间消息传递,未构建标准辩论场景,无法适配假新闻检测的深度推理需求。
3. 方法(Methodology)
3.1 任务定义
将假新闻检测转化为多LLM智能体的交互式辩论任务:N个智能体分为正方(支持新闻真实)与反方(质疑新闻真实),通过辩论生成日志D,由Synthesis Agent生成报告S,Analysis Agent基于S与原始新闻F预测真实性。
3.2 TED框架核心组件
- DebateFlow Agents:遵循林肯-道格拉斯辩论格式,分四个阶段:开场陈述(提出初始论据)、交叉质询与反驳(质疑对方观点)、总结陈述(强化核心论据),所有交互记录于$D=\bigcup_{k=1}^{3} D^{(k)}$。
- InsightFlow Agents:
- Synthesis Agent:基于辩论日志,从“具体细节、可靠来源、语气风格、情感语言、多方验证”五个维度生成综合报告S。
- Analysis Agent:通过角色感知编码器生成节点嵌入,构建辩论图并经GAT处理,结合新闻-辩论交互注意力机制,输出最终预测结果。
3.3 算法流程
详细定义了从输入新闻F到输出预测值ŷ与解释R的完整步骤,包括智能体角色分配、辩论阶段执行、日志汇总、报告生成与真实性判断。
4. 实验(Experiment)
4.1 实验设置
- 数据集:ARG-EN(英文)与ARG-CN(中文),分别源自GossipCop与Weibo21,经去重与时间划分避免数据泄露。
- 基线模型:三类方法——LLM-Only(GPT-3.5-turbo、GPT-4o-mini)、SLM-Only(BERT、EANN等)、LLM+SLM(ARG、SuperICL等)。
- 实现细节:基于Python与Mesa框架构建智能体,LLM采用GPT-4o-mini,Analysis Agent使用微调后的BERT模型,优化器为Adam,基于NVIDIA 3090 GPU训练。
4.2 主要结果
- TED在两个数据集上的macF1与准确率均排名第一(ARG-EN:macF1=0.803、Acc=0.892;ARG-CN:macF1=0.795、Acc=0.798),显著优于所有基线。
- 单独LLM与SLM性能有限,LLM+SLM混合方法虽有提升,但未及TED的结构化辩论优势;TED优于ChatEval的多智能体策略,证实辩论流程的有效性。
5. 分析与讨论(Analysis and Discussion)
5.1 消融实验
- 移除DebateFlow Agents:macF1下降2.3%-2.8%,证实结构化辩论的核心作用。
- 移除Synthesis Agent:macF1下降1.1%-2.4%,说明辩论总结对整合论据的重要性。
- 移除Analysis Agent:macF1下降4.5%-8.0%,凸显新闻-辩论交互分析的关键价值。
5.2 不同骨干模型适配性
- 闭源模型:TED适配GPT-4o-mini与Deepseek,性能均优于单独使用该LLM,GPT-4o-mini略具优势。
- 开源模型:TED在Qwen-2.5(7B)、Llama 3.1(8B/70B)上均有性能提升,Qwen-2.5适配性最佳,证实框架的强泛化能力。
5.3 案例研究
通过“SNL明星恋情”假新闻辩论案例,展示TED的可解释性:正反方经多阶段辩论后,基于论据细节、语气客观性等因素得出判断,辩论报告为检测结果提供清晰依据。
6. 结论(Conclusion)
总结TED框架的核心价值:通过结构化多智能体辩论,充分释放LLM推理能力,在假新闻检测中实现“准确性”与“可解释性”的双重提升。该研究为负责任信息系统的开发提供了新思路,助力用户应对数字信息复杂性。
7. 附录(Appendix)
提供中文数据集对应的Prompt模板,及代码开源地址(https://github.com/LiuYuHan31/TED_fake-news-detction)。