Context-Aware Sentiment Forecasting via LLM-based Multi-Perspective Role-Playing Agents
Context-Aware Sentiment Forecasting via LLM-based Multi-Perspective Role-Playing Agents
论文概览
本文假设大语言模型(LLMs)可通过理解复杂事件上下文、提取用户隐式特征并模拟多视角角色互动,解决社交媒体情感预测中上下文依赖和用户异质性问题;提出基于LLM的多视角角色扮演(MPR)框架,整合特征提取、主观/客观角色代理及迭代修正模块;在2012年飓风桑迪和2020年美国大选数据集上的实验表明,该框架在微观(准确率、Macro F1)和宏观(JSD)层面均显著优于现有基线方法;结论证实该框架能精准预测用户未来情感,为社会管理、灾害应对等场景提供前瞻性支持。
核心问题
社交媒体用户情感受实时事件发展影响具有强上下文依赖性,但现有研究存在三大局限:1. 传统情感分析多为回顾性,难以预测未来情感趋势;2. 现有方法忽略事件动态上下文,仅聚焦用户间相互影响,适用性有限;3. 社交媒体用户匿名性导致用户特异性特征获取困难,且情感演化复杂微妙,难以建模不同用户对同一事件的差异化响应。本文旨在解决“如何基于实时事件上下文和用户特征,精准预测社交媒体用户个体及群体未来情感”的核心问题。
主要贡献
- 明确将社交媒体情感预测形式化为融合外部上下文的推理问题,聚焦实时事件下用户未来情感响应预测,填补现有研究的前瞻性空白。
- 提出基于LLM的隐式特征提取方法,从用户生成内容中提取文本语气(ν)和事件态度(α)两类关键特征,丰富用户特异性建模维度。
- 设计多视角角色扮演框架:主观代理模拟普通用户生成未来评论,微调的客观“心理学家”代理保证行为一致性,结合迭代修正机制,提升预测的精准度和 nuance。
研究方法
本文提出的上下文感知情感预测框架包含四大核心组件,整体流程为“特征提取→主观生成→客观校验→迭代优化”: 1. 特征提取:通过LLM从用户历史评论中提取文本语气ν(如“观察性、轻蔑性、焦虑”)和事件态度α(如“顺从、幽默、轻蔑”),公式分别为 νtu = LLM(𝒞tu, iν) 和 αtu = LLM(νtu, 𝒞tu, ℰtu, iα),其中 𝒞tu 为用户t时刻前的评论,ℰtu 为事件上下文,iν 和 iα 为对应任务指令。 2. 主观角色扮演代理:基于提取的特征(ν、α)、用户属性 𝒜tu 及历史评论,通过LLM模拟用户浏览关注者评论后生成未来评论,公式为 ϕt′u = LLMts(ℱtu, ℰtu, t′, is),其中 ℱtu 为关注者评论,t′ 为预测时间点。 3. 客观角色扮演代理:通过LoRA微调Llama 3 8B作为“行为心理学家”,分析生成评论与用户历史行为的一致性,公式为 θt′u = LLMto(νtu, αtu, 𝒞tu, ϕt′u, io),θt′u 为一致性分析结果。 4. 迭代修正:若生成评论不一致,将客观代理的分析结果反馈给主观代理,迭代生成修正评论,公式为 ϕt′u = LLMts(θt′u, 𝒜tu, 𝒞tu, ϕt′u, ig),迭代上限设为3次以平衡效率与效果。
各章节详解
1. 引言(Introduction)
本章首先阐述社交媒体情感研究的应用价值,涵盖社会研究、市场营销和公共管理等领域(如灾害救援中通过负面情感定位重点区域)。随后区分情感预测与传统回顾性情感分析的差异,指出情感预测的前瞻性价值。接着分析现有方法的不足:传统模型忽略事件上下文,LLM虽具备上下文理解能力,但存在用户特征获取难、情感演化建模复杂等问题。最后明确本文研究目标,概述多视角角色扮演框架的核心思路,并列出三大主要贡献。
2. 相关工作(Related Work)
2.1 情感研究
现有情感研究多聚焦集体情感演化建模,如基于社会网络的Agent模型(SINN)、融合概率语言方法的DeGroot模型等,但这些方法仅考虑用户间相互作用,未融入事件上下文,实际场景适用性受限。本文框架首次将实时事件发展作为核心上下文,结合用户个体特征建模。
2.2 LLM角色扮演
现有LLM角色扮演方法需依赖大量角色中心化数据(如性格、社会地位),适用于娱乐角色或历史人物模拟,但在社交媒体场景中,获取用户隐私数据不现实且不道德,导致方法泛化性不足。本文通过提取用户生成内容中的隐式特征,避免对隐私数据的依赖,提升了方法的实用性。
3. 方法论(Methodology)
3.1 问题定义
传统情感分析定义为 σ = FSA(c),其中 FSA 为情感分析函数,c 为现有评论。情感预测则被形式化为时序推理任务:σt′ = FSF(⋃τ ≤ tτ),其中 τ 为t时刻前的所有信息(用户评论、事件上下文等),t′ ≥ t 为预测时间点,FSF 为情感预测函数。
3.2 整体框架
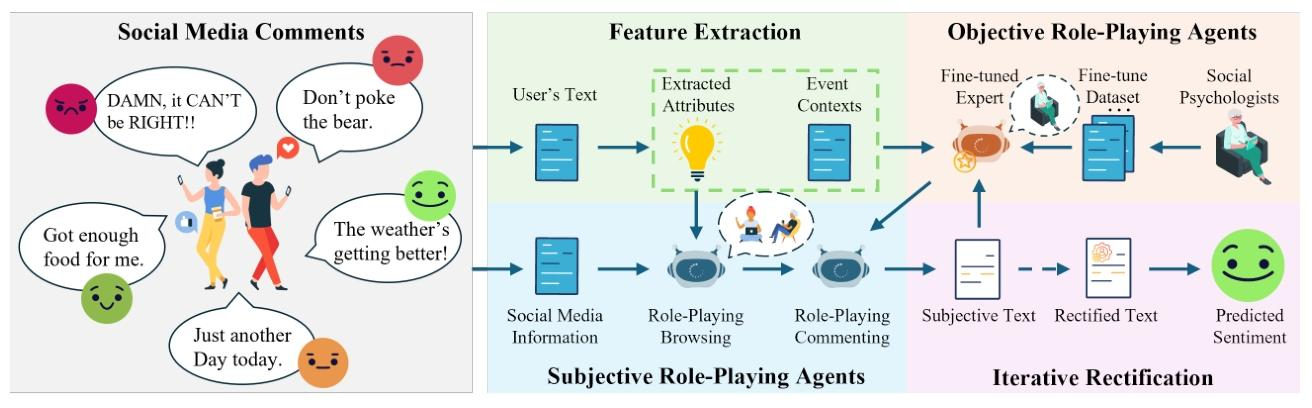
框架包含四大组件(特征提取、主观代理、客观代理、迭代修正),核心逻辑是通过LLM理解复杂上下文,提取用户隐式特征,再通过双角色互动模拟用户情感响应过程,确保预测的一致性和准确性。
3.3-3.6 核心组件细节
- 特征提取聚焦文本语气(稳定特征)和事件态度(动态特征),均通过LLM生成3个描述性形容词量化。
- 主观代理采用Gemma 2 9B和Mistral NeMo 12B,避免主流模型的内容过滤限制,更适配社交媒体真实数据。
- 客观代理通过25,000组专家标注数据微调,标注者间一致性达70%(Fleiss’ Kappa=0.796),确保分析可靠性。
- 迭代修正通过反馈机制降低生成评论的随机性,提升与用户行为模式的契合度。
4. 实验(Experiment)
4.1 实验设置
- 数据集:采用两个真实事件数据集——2012年飓风桑迪(5255万条推文,1375万用户)和2020年美国大选(170万条推文),分别选取两个关键时间点(T1/T2为飓风前后,T3/T4为大选辩论后/拜登宣布胜选后)进行预测。
- 基线方法:包括5类主流方法——Voter、DeGroot(社会模型类)、SLANT+、NN(神经网络类)、SINN(社会学启发神经网络类)。
- 评估指标:微观层面用准确率(Accuracy)和Macro F1评估个体预测效果;宏观层面用Jensen-Shannon散度(JSD)衡量群体情感分布相似度,JSD公式为 $JSD(p \| q)=\frac{1}{2} KL\left(p \| \frac{p+q}{2}\right)+\frac{1}{2} KL\left(q \| \frac{p+q}{2}\right)$,值越小表示预测分布与真实分布越接近。
- 实现细节:主观代理采用Gemma 2 9B和Mistral NeMo 12B,客观代理为微调后的Llama 3 8B,学习率 η = 1 × 10−4,迭代次数上限n=3。
4.2 实验结果
- 宏观层面:MPR框架(MPR_G和MPR_M)的JSD值比基线低一个数量级,如飓风桑迪数据集纽约地区T1时刻,MPR_G的情感分布JSD仅为0.0456,远低于SINN的0.1504。
- 微观层面:MPR框架在两个数据集上均优于基线,如飓风桑迪数据集新泽西地区T2时刻,MPR_M的准确率达0.438,比SINN(0.364)提升20.3%;大选数据集T4时刻,MPR_G的Macro F1达0.397,比SINN(0.183)提升116.9%。
4.3 消融研究
通过移除核心组件验证有效性:1. 移除评论生成模块(MPR-RP)后,性能接近随机猜测,证明模拟用户行为的重要性;2. 移除特征提取模块(MPR-FE)后,随机性显著增加,验证特征提取的价值;3. 移除客观代理(MPR-OB)后,性能略有下降,凸显一致性校验的作用。此外,仅预测情感极性时,框架准确率最高达63.9%。
4.4 讨论
分析了性能差异的原因:大选数据集依赖新闻和社交媒体信息,预测效果优于飓风桑迪数据集(15%用户情感不受社交媒体信息影响)。同时提出潜在应用场景:灾害心理状态预测、社会事件极端情感预警、金融市场趋势分析等。
5. 结论(Conclusion)
总结本文核心贡献:提出上下文感知的多视角角色扮演框架,将情感预测形式化为推理问题,通过LLM提取隐式特征并模拟多角色互动,实现个体和群体层面的精准情感预测。实验验证了框架在两个真实数据集上的优越性,为社交媒体情感预测提供了新范式。
6. 局限性(Limitations)
- 模型依赖性:主流LLM(如GPT系列)受内容过滤限制,无法处理社交媒体中的不当或强负面内容,影响方法适用性;2. 模态单一:仅利用文本数据,未整合图像、视频等多模态信息,可能遗漏关键情感线索。未来可探索多模态融合和更灵活的模型适配方案。
附录(Appendix)
补充了指令示例、LLM微调细节(如LoRA配置、训练损失曲线)、数据集时间线、数据预处理步骤(事件重命名避免LLM后验知识干扰、用户筛选标准)及不同LLM(如Llama 3.1)的性能对比,为方法复现提供支持。