GenSim: A General Social Simulation Platform with Large Language Model based Agents
GenSim: A General Social Simulation Platform with Large Language Model based Agents
论文概览
本文假设现有基于大语言模型(LLM)代理的社交模拟平台局限于特定场景、支持代理数量有限且缺乏有效纠错机制,同时社会科学传统实证研究存在高成本、可控性差等缺陷,因此提出通用、大规模、可纠错的LLM代理社交模拟平台GenSim,通过设计通用框架、采用分布式并行技术及PPO/SFT纠错策略,经实验验证其在大规模模拟效率和纠错有效性上的优势,最终为社会科学研究提供新范式。
核心问题
- 社会科学传统研究依赖真实人类数据,存在高成本、可控性差、可重复性低等固有缺陷,难以开展大规模实验。
- 现有LLM代理社交模拟研究多聚焦特定场景,支持代理数量少(通常不超过1000),无法还原真实世界大规模人群互动。
- 现有模拟平台缺乏误差校正机制,模拟过程中出现的偏差会随模拟推进累积放大,影响结果可靠性。
主要贡献
- 提出首个通用、大规模、可纠错的LLM代理社交模拟平台GenSim,突破现有研究的场景局限和规模瓶颈。
- 提供详细的平台使用示例和三类默认场景(就业市场、推荐系统、小组讨论),降低用户定制化模拟的门槛。
- 开展多维度实验,系统验证了平台在大规模模拟效率、纠错机制有效性等方面的性能。
研究方法
- 框架设计:构建包含单代理、多代理、环境三大核心模块的通用框架,支持代理配置、互动生成和全局调度的灵活定制。
- 大规模支撑:采用基于Actor的模型和分布式并行技术,实现最高10万级代理的并行模拟,适配多GPU加速。
- 纠错机制:设计LLM自动评估(GPT-4o)和人类反馈两种策略,通过PPO(基于评分S)和SFT(基于修正结果a′)微调基础模型。
- 实验验证:基于MovieLens32M数据集验证规模对模拟稳定性的影响,以LLaMA3-8B为基础模型,在就业市场、推荐系统场景下测试效率和纠错效果。
各章节详解
1. 引言(Introduction)
本章首先阐述社会科学研究的核心价值,以及传统实证研究(如受控实验、实地实验)面临的高成本、可控性差、伦理风险等问题。随后介绍LLM的发展催生“AI for Social Science”新方向,即利用LLM代理模拟人类行为开展研究,并列举Generative Agent、RecAgent等代表性工作的成果。最后指出现有LLM代理模拟研究在场景通用性、规模扩展性和误差校正上的三大局限,明确GenSim平台的研发目标和核心定位。
2. GenSim的核心特征(Features of GenSim)
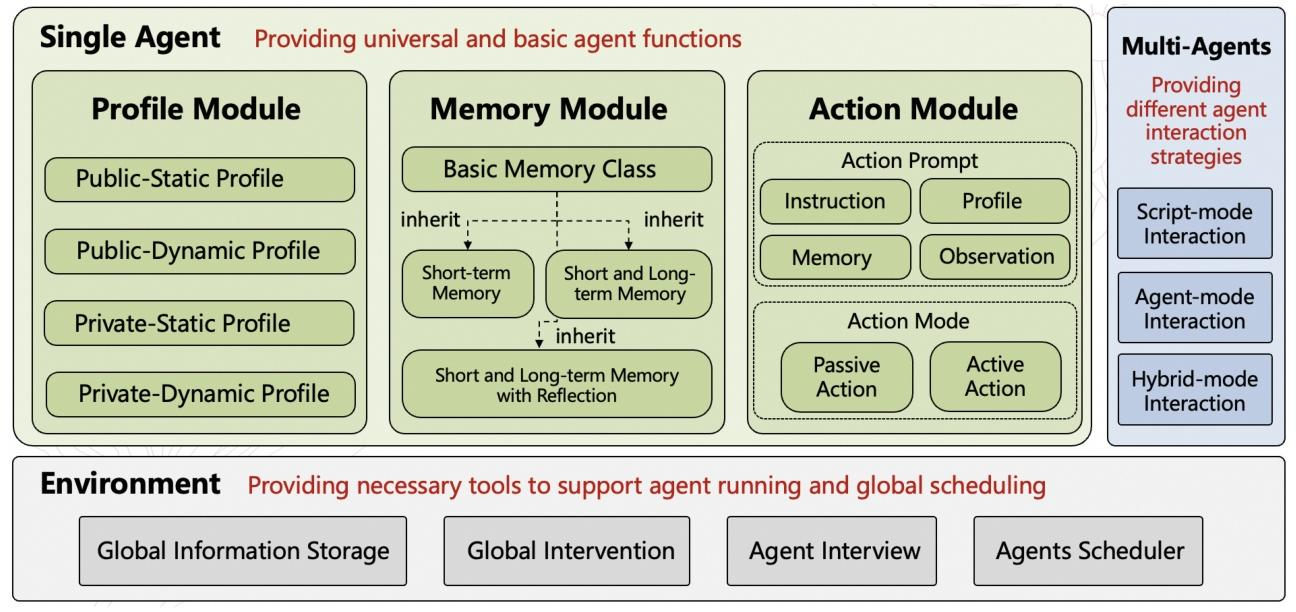
2.1 通用模拟框架(General Simulation Framework)
框架包含三大模块,支持用户灵活定制模拟场景: - 单代理模块:允许配置代理的公开/私有属性(如性别、收入)、记忆组件(短期/长期记忆、反思机制)和行为驱动(基于LLM提示词,整合 profile 和记忆)。 - 多代理模块:设计脚本模式(LLM以第三方视角一次性生成互动)和代理模式(各代理以第一视角基于互动历史生成行为)两种互动策略。 - 环境模块:存储模拟所需的全局信息(如推荐算法),支持用户全局干预(用于反事实推理),并提供代理查询、访谈等功能。 平台同时提供三类默认场景,为用户提供基础代码模板。
2.2 大规模模拟(Large-scale Simulation)
针对小样本代理模拟结果波动大的问题,平台通过技术优化支持10万级代理规模: - 技术手段:采用Actor模型实现自动并行优化,设计动态工作流适配LLM的概率性输出,支持多机并行突破单机算力限制。 - 实验验证:基于MovieLens32M数据集的实验显示,代理规模从3.2K提升至3.2M时,模拟结果波动(各评分标准差之和)显著降低;10万代理在就业市场和推荐系统场景下单轮模拟耗时分别为15492秒和3024秒,且多GPU部署可显著降低耗时。
2.3 模拟误差校正(Simulation Error Correction)
为解决模拟偏差累积问题,提出两类纠错策略: - 纠错路径:LLM自动纠错(GPT-4o评分/修正,高效无人工干预)和人类反馈纠错(精准但耗时),均通过PPO或SFT微调基础模型。 - 实验结果:单轮实验中,PPO和SFT均能提升模拟合理性(1-5分评分体系),且SFT效果优于PPO;多轮实验中,无纠错组性能持续不佳,而PPO和SFT组性能随轮次增加不断提升,验证了纠错机制的长期有效性。
3. GenSim的使用方法(Usages of GenSim)
本章介绍平台的核心操作流程,配合界面展示(首页、配置页、模拟页、标注页): 1. 启动与配置:用户点击“Get Started”,指定模拟场景、代理数量、LLM参数等核心配置。 2. 模拟运行:平台顶部提供代理搜索功能,中部展示多代理互动行为,右侧支持查看代理信息、系统干预和代理交互。 3. 结果标注与模型迭代:模拟结束后用户可标注结果,平台基于标注数据微调LLM,用于后续模拟优化。 同时提供YouTube演示链接供用户获取详细操作指导。
4. 相关工作(Related Work)
4.1 社会科学研究方法
对比传统实验室实验、实地实验和随机对照试验(RCT)的特点,强调其在可逆性、成本、伦理上的局限,凸显LLM代理模拟的互补价值。
4.2 多代理模拟
梳理现有LLM代理模拟工作的应用场景(日常生活、推荐系统、经济市场等)和代理规模,通过表格对比显示,GenSim是唯一支持通用场景、10万级代理且具备自进化(纠错)能力的平台。
5. 结论、局限与伦理考量(Conclusions, Limitation, Ethical Considerations)
结论
总结GenSim平台的核心价值,即通过通用框架、大规模支撑和纠错机制,为社会科学研究提供低成本、高可控、可重复的新工具,推动“AI for Social Science”领域发展。
局限
- 跨社会文化场景的泛化能力尚未充分验证,复杂文化规范和制度环境的模拟准确性需进一步验证。
- 依赖LLM作为评估者可能引入偏差,缺乏大规模人类标注验证评分一致性。
- LLM在伦理困境等场景中的纠错可靠性尚未得到检验。
伦理考量
明确平台数据来源于公开数据集或LLM生成的合成数据,严格遵循数据使用许可,无伦理风险。