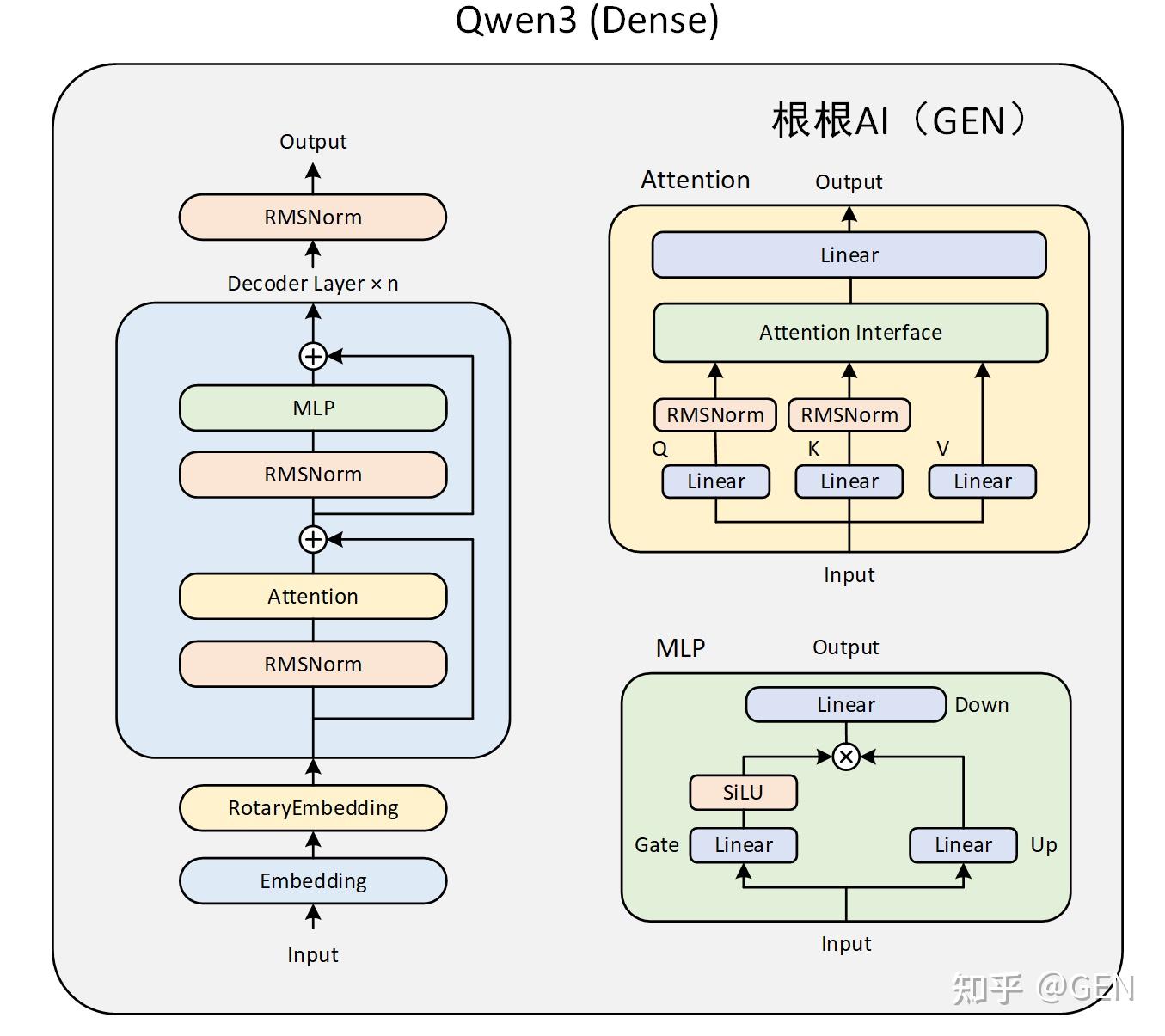
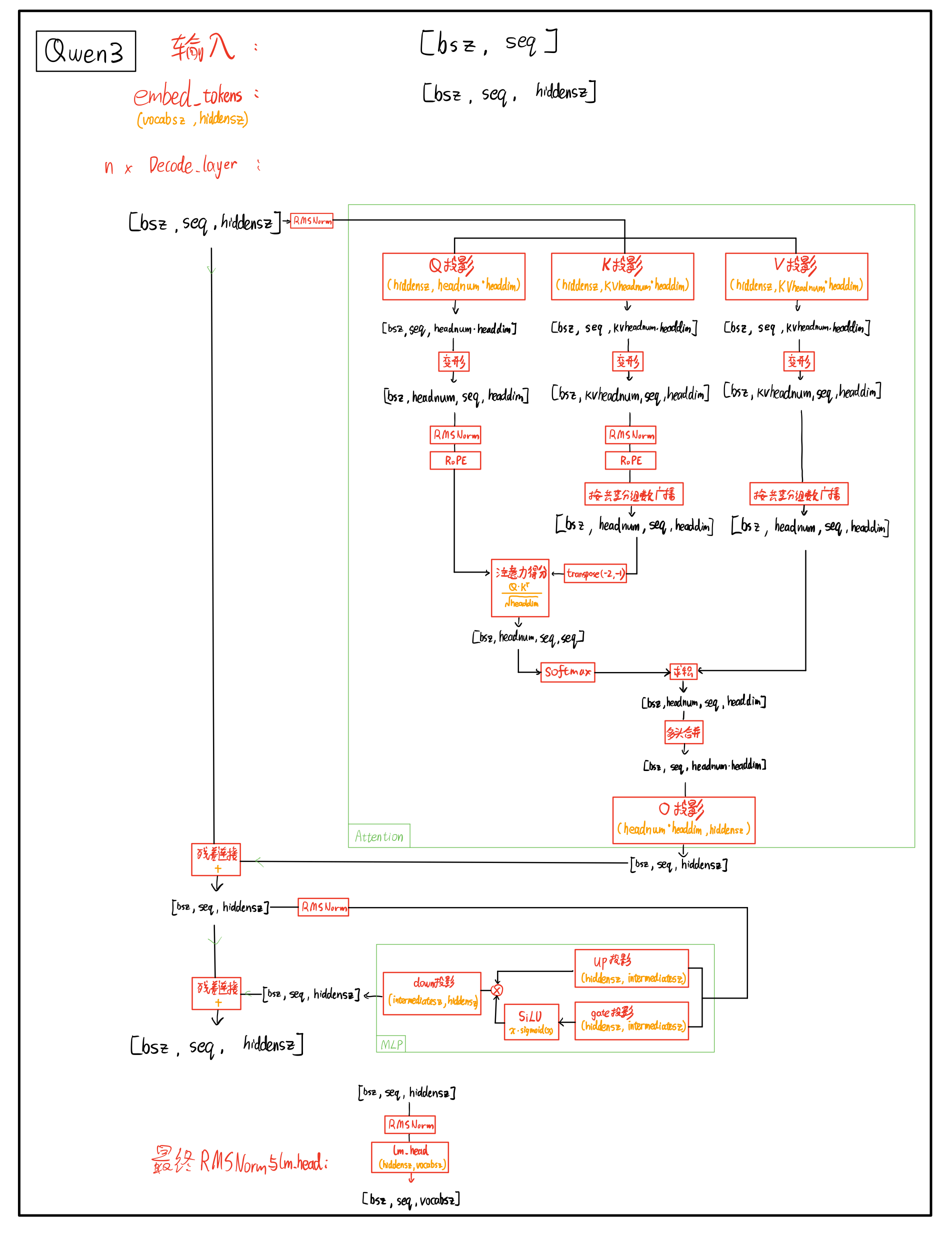
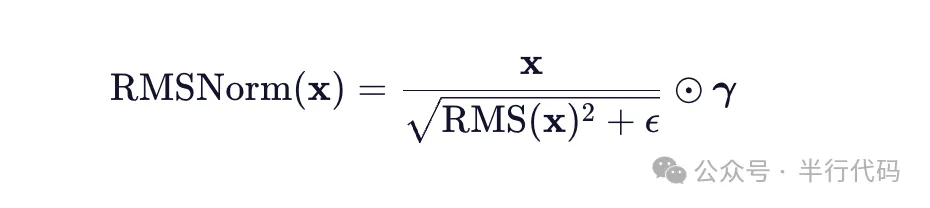1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
| def apply_rotary_pos_emb(q, k, position_ids, head_dim, rope_theta=1000000.0):
device = q.device
inv_freq = 1.0 / (rope_theta ** (torch.arange(0, head_dim, 2, dtype=torch.float32, device=device) / head_dim))
freqs = position_ids.unsqueeze(-1).float() * inv_freq.unsqueeze(0).unsqueeze(0)
emb = torch.cat([freqs, freqs], dim=-1)
cos = emb.cos().unsqueeze(1).to(q.dtype)
sin = emb.sin().unsqueeze(1).to(q.dtype)
def rotate_half(x):
x1, x2 = x.chunk(2, dim=-1)
return torch.cat((-x2, x1), dim=-1)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
class MLP(nn.Module):
def __init__(self,config):
super().__init__()
self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False)
self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False)
self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False)
def forward(self, x):
ret=self.down_proj(F.silu(self.gate_proj(x)) * self.up_proj(x))
return ret
class SelfQwen3RMSNorm(nn.Module):
def __init__(self, hidden_size,eps):
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)
class Attention(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.num_key_value_heads = config.num_key_value_heads
self.head_dim = config.head_dim
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
self.q_norm = SelfQwen3RMSNorm(self.head_dim, eps=config.rms_norm_eps)
self.k_norm = SelfQwen3RMSNorm(self.head_dim, eps=config.rms_norm_eps)
self.rope_theta = config.rope_theta
def forward(self, hidden_states, position_ids=None, attention_mask=None):
bsz, q_len, _ = hidden_states.size()
# 得到QKV
query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
# QK归一化
query_states = self.q_norm(query_states)
key_states = self.k_norm(key_states)
# 应用位置编码
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, position_ids, self.head_dim, self.rope_theta)
# 多头分组查询
if self.num_key_value_groups > 1:
# head_dim维度扩大
key_states = key_states.unsqueeze(2).expand(-1, -1, self.num_key_value_groups, -1, -1).flatten(1, 2)
value_states = value_states.unsqueeze(2).expand(-1, -1, self.num_key_value_groups, -1, -1).flatten(1, 2)
# 计算注意力得分
attn_weights = torch.matmul(query_states, key_states.transpose(-2, -1)) / (self.head_dim ** 0.5)
if attention_mask is not None:
attn_weights = attn_weights + attention_mask
# 计算权重
attn_weights = torch.softmax(attn_weights, dim=-1, dtype=torch.float32).to(hidden_states.dtype)
# 加权求和
attn_output = torch.matmul(attn_weights, value_states)
# 合并多头
attn_output = attn_output.transpose(1, 2).contiguous().view(bsz, q_len, -1)
# 输出投影
attn_output = self.o_proj(attn_output)
return attn_output
class DecoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.self_attn = Attention(config)
self.post_attention_layernorm = SelfQwen3RMSNorm(config.hidden_size,config.rms_norm_eps)
self.mlp=MLP(config)
self.input_layernorm=SelfQwen3RMSNorm(config.hidden_size,config.rms_norm_eps)
self.hook_attn_output = HookPoint()
def forward(self, hidden_states,position_ids=None, attention_mask=None):
residual = hidden_states
hidden_states = self.input_layernorm(hidden_states)
attn_output = self.self_attn(hidden_states, position_ids, attention_mask)
attn_output = self.hook_attn_output(attn_output)
hidden_states = residual + attn_output
residual = hidden_states
hidden_states = self.post_attention_layernorm(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
return hidden_states
class SelfQwen3Model(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
self.layers = nn.ModuleList([DecoderLayer(config) for _ in range(config.num_hidden_layers)])
self.norm = SelfQwen3RMSNorm(config.hidden_size,config.rms_norm_eps)
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size,bias=False)
self.lm_head.weight = self.embed_tokens.weight
def forward(self, input_ids):
bsz,seq_len=input_ids.shape
position_ids=torch.arange(seq_len, dtype=torch.long, device=input_ids.device).unsqueeze(0)
causal_mask = torch.triu(
torch.full((seq_len, seq_len), float('-inf'), dtype=torch.float32, device=input_ids.device),
diagonal=1
)
causal_mask = causal_mask.unsqueeze(0).unsqueeze(0)
hidden_states = self.embed_tokens(input_ids)
for layer in self.layers:
hidden_states = layer(hidden_states, position_ids=position_ids, attention_mask=causal_mask)
hidden_states = self.norm(hidden_states)
logits = self.lm_head(hidden_states)
return logits
|